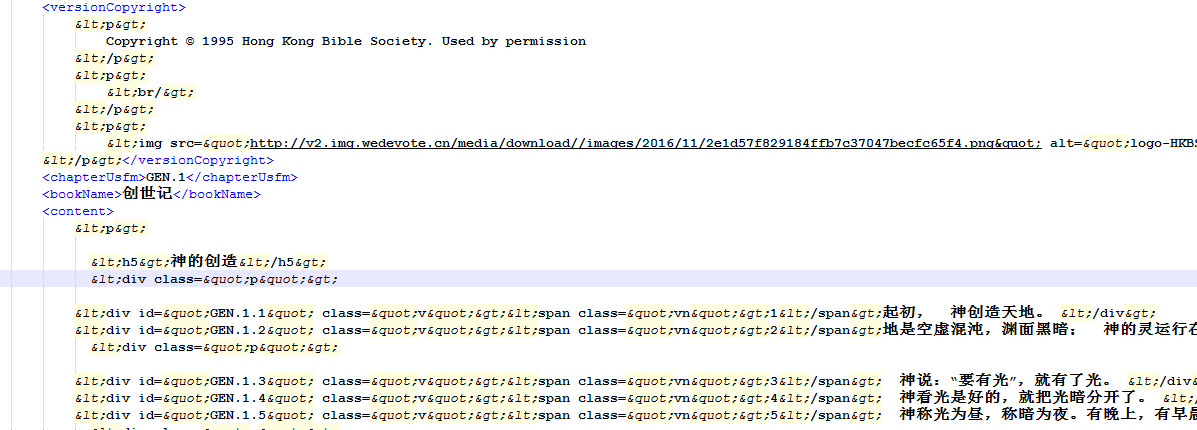

xml文件中标签内的值含有HTML标签快,div啊什么的,想要删除他们该怎么做??

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


1条回答 默认 最新
 你知我知皆知 2024-08-08 08:28关注
你知我知皆知 2024-08-08 08:28关注以下回答参考 皆我百晓生、券券喵儿 等免费微信小程序相关内容作答,并由本人整理回复。
要从XML文件中删除包含HTML标签的行,可以使用Python中的
lxml库来解析XML数据,并在遍历过程中检查元素是否包含特定的HTML标签。以下是一个简单的示例:from lxml import etree # XML 文件路径 xml_file_path = 'your_xml_file.xml' # 解析XML文件 tree = etree.parse(xml_file_path) root = tree.getroot() for element in root.iter(): # 检查元素是否包含特定的HTML标签 if element.tag == "versionCopyright" and element.text.startswith("<"): print("Found versionCopyright tag with HTML content:", element.text) elif element.tag == "chapterUsfm" and element.text.startswith("<"): print("Found chapterUsfm tag with HTML content:", element.text) # 这里可以根据你的需求进一步处理这些元素注意:这个例子仅用于演示如何查找和打印包含HTML标签的元素。实际应用中,你可能还需要根据具体的需求对这些元素进行进一步的操作(例如替换、清理等)。
此外,确保你的环境已安装了
lxml库。如果没有,请使用以下命令进行安装:pip install lxml然后,将上述代码保存到一个
.py文件中,例如命名为delete_html_tags.py。最后,通过运行此脚本来查看输出结果。解决 无用评论 打赏举报 分享
- 2016-12-20 20:06回答 1 已采纳 According to your output Your code is correct, except just you need to put your Table inside your
- 2009-11-02 11:46回答 2 已采纳 I think the functions like the_post() and the_title() will immediately output the value rather tha
- 2012-08-21 07:14回答 1 已采纳 The point of the cache is to prevent the (resource expensive) code from running multiple times if
- 2020-12-18 18:43`strip_tags()`是PHP中一个非常实用的字符串处理函数,它的主要作用是移除字符串中的HTML、XML以及PHP标签。这个函数在处理用户输入、防止XSS(跨站脚本攻击)或者格式化数据时非常有用。下面我们将详细介绍`strip_...
- 2018-11-23 00:30回答 1 已采纳 The following is the problematic line. uploadSingleFile(this.files[i+1], i+1); You want the val
- 2011-01-20 20:20回答 1 已采纳 The first function is attempting to open up and XML HTTP request, allowing the clients-side script
- 2015-06-23 19:06回答 1 已采纳 The ->menu_items also does not need to be there, since it is the root node of the XML document.
- 2021-06-18 06:49段丞博的博客 例如我们常用到的div,o,ul,dl,table,h1...h6等,这些都是块级元素;而像a,b,i,em,img,span等就是内联元素了。在开发过程中,我们避免不了各种元素的嵌套,但是有时候我们在不知不觉中就错误地嵌套元素了。...
- 2011-11-25 14:32回答 2 已采纳 If all you want is just the second one you can use DOM. It's simpler. $dom->loadXML(<<&l
- 2017-04-17 13:50回答 1 已采纳 Change your function signature to take the value by reference: function checkTranslation(&$foo) {
- 回答 2 已采纳 I don't see an obvious way to do much caching on the pricerequest requests that are basket-depende
- 2020-10-21 12:21PHP的DOMDocument在加载HTML或XML时,会尝试通过文档中的meta标签来确定字符编码。如果没有明确的charset声明,DOMDocument通常会假设文档是用ISO-8859-1编码的。然而,在保存XML时,DOMDocument会默认使用UTF-8编码...
- 2013-09-05 08:23回答 2 已采纳 G-WAN gives the output as plain text (no style nothing), and if i remove the exit(200), it give
- 2021-06-14 06:07培根悖论唠唠嗑的博客 段落标签段落:是英文paragraph的缩写。属性:align='属性值':对齐方式。属性值包括:left、center、right示例:效果:ok,下面这几句话,大家一定牢牢记住。HTML标签是分等级的。HTML将所有的标签分为两种:1.文本...
- 2021-06-10 10:12deep go的博客 利用freemarker做html页面静态化1.1. 什么是freemarkerFreeMarker是一个用Java语言编写的模板引擎,它基于模板来生成文本输出。...它不仅可以用作表现层的实现...目前企业中:主要用Freemarker做静态页面或是页面展示1.2...
- 没有解决我的问题, 去提问



悬赏问题
- ¥18 关于#贝叶斯概率#的问题:这篇文章中利用em算法求出了对数似然值作为概率表参数,然后进行概率表计算,这个概率表是怎样计算的呀
- ¥15 Android Navigation: 某XDirections类不能自动生成
- ¥20 C#上传XML格式数据
- ¥15 elementui上传结合oss接口断点续传,现在只差停止上传和继续上传,各大精英看下
- ¥100 单片机hardfaulr
- ¥20 手机截图相片分辨率降低一半
- ¥50 求一段sql语句,遇到小难题了,可以50米解决
- ¥15 速求,对多种商品的购买力优化问题(用遗传算法、枚举法、粒子群算法、模拟退火算法等方法求解)
- ¥100 速求!商品购买力最优化问题(用遗传算法求解,给出python代码)
- ¥15 虚拟机检测,可以是封装好的DLL,可付费