
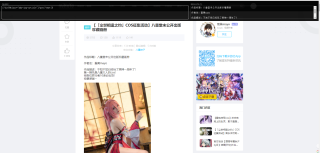
如上图,理论上是能提取出来文字的
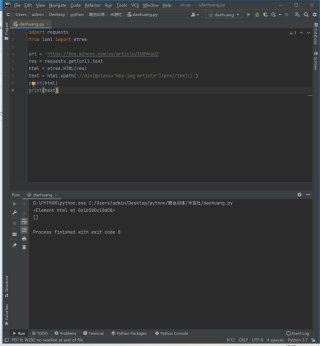
但是,提取出来是空列表
对了,还有一个问题就是为什么有些会显示这个:<Element html at 0x1b580c10d08>
之前爬小说图片什么的,都是显示html的内容
我百度上去找方法都不行,因为我的列表都是空值

但是,提取出来是空列表
对了,还有一个问题就是为什么有些会显示这个:<Element html at 0x1b580c10d08>
之前爬小说图片什么的,都是显示html的内容
我百度上去找方法都不行,因为我的列表都是空值
 分享
分享
你检查下这个网页中的内容是不是通过js代码读取外部json数据来动态更新的。
requests只能获取网页的静态源代码,动态更新的内容取不到。
对于动态更新的内容要用selenium 来爬取。
或者是通过F12控制台分析页面数据加载的链接,找到真正json数据的地址进行爬取。
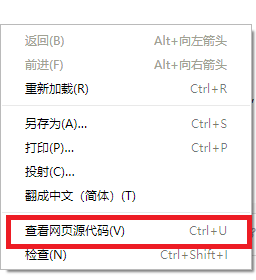
在页面上点击右键,右键菜单中选 "查看网页源代码"。
分享 系统已结题
10月16日
系统已结题
10月16日 已采纳回答
10月8日
创建了问题
9月30日
已采纳回答
10月8日
创建了问题
9月30日


