1 在爬取某知名文库时,出现了抓过的包找不到的现象。
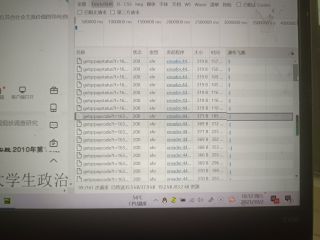
这是我第一次抓的包:
这是我第二次准备抓包时:
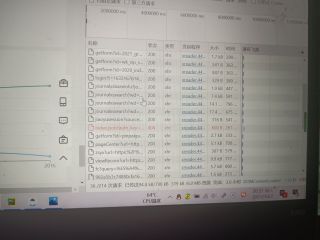
望解答。
2 另外第二张图中那个红色的包是什么意思呢?

1 在爬取某知名文库时,出现了抓过的包找不到的现象。
这是我第一次抓的包:
 分享
分享 巧了我也没有遇到你出现的那两个XHR;
红色代表请求失败,404一般是链接所指的网页不存在。
分享 系统已结题
10月13日
系统已结题
10月13日 已采纳回答
10月5日
创建了问题
10月2日
已采纳回答
10月5日
创建了问题
10月2日

