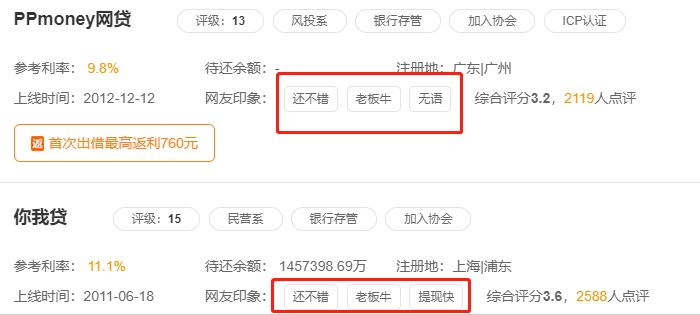
萌新学习python爬虫,在爬取网贷之家平台信息的时候,通过xpath将某一平台的网友印象三个关键词保存在一个数组中,输出到excel中。
现在我希望能够把该页面上25个平台信息都爬取到并保存,请问xpath怎么写循环?这里的25个信息代码结构是一模一样的,只有li从[1]-[25]。谢谢
import requests
import pandas as pd
from lxml import etree
from fake_useragent import UserAgent
ua = UserAgent()
headers['User-Agent']=ua.random
url = 'https://www.wdzj.com/dangan/search?filter=e1¤tPage=1'
response = requests.get(url,headers = headers).text
s = etree.HTML(response)
file_yinxiang = []
file_yinxiang1 = s.xpath('//*[normalize-space(@id)="showTable"]/ul/li[1]/div[2]/a/div[5]/span/text()')#实现li从1-25的循环
file_yinxiang.append(file_yinxiang1)
df = pd.DataFrame(file_yinxiang)
df.to_excel('wdzj_p2p.xlsx')
网上查了很多资料,并不是很清楚,目前不循环是这个结果:

这是网页上我要爬取的内容: