问题如题,想爬取的页面为百度文库,他的文字形式为:
想知道该怎么写代码。

问题如题,想爬取的页面为百度文库,他的文字形式为:
想知道该怎么写代码。
 分享
分享
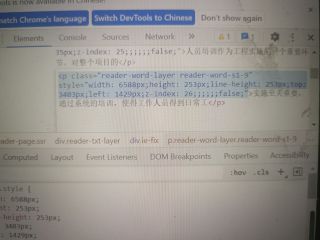
可以看到,这些p标签拥有固定的class:“reader-word-layer”,就可以使用driver.find_elements_by_class_name("reader-word-layer")获取到装有这些标签的容器。
此后遍历容器,使用.getText()方法即可获取到这些标签内的文本,然后将它们拼接成字符串即可。
相关其他问题欢迎私信我!
分享 系统已结题
10月15日
系统已结题
10月15日 已采纳回答
10月7日
修改了问题
10月7日
创建了问题
10月7日
已采纳回答
10月7日
修改了问题
10月7日
创建了问题
10月7日


