
部分源码如下
<ol class="grid_view">
<li>
<div class="item">
<div class="pic">
<em class="">1</em>
<a href="https://movie.douban.com/subject/1292052/">
<img width="100" alt="肖申克的救赎" src="https://img2.doubanio.com/view/photo/s_ratio_poster/public/p480747492.webp" class="">
</a>
</div>
<div class="info">
<div class="hd">
<a href="https://movie.douban.com/subject/1292052/" class="">
<span class="title">肖申克的救赎</span>
<span class="title"> / The Shawshank Redemption</span>
<span class="other"> / 月黑高飞(港) / 刺激1995(台)</span>
</a>
<span class="playable">[可播放]</span>
</div>
<div class="bd">
<p class="">
导演: 弗兰克·德拉邦特 Frank Darabont 主演: 蒂姆·罗宾斯 Tim Robbins /...<br>
1994 / 美国 / 犯罪 剧情
</p>
<div class="star">
<span class="rating5-t"></span>
<span class="rating_num"property="v:average">9.7</span>
<span property="v:best" content="10.0"></span>
<span>2424702人评价</span>
</div>
<p class="quote">
<span class="inq">希望让人自由。</span>
</p>
</div>
</div>
</div>
</li>
目标是使用re库编写一个能够匹配一个电影的名称,年份,评分的正则表达式,我将上面的代码保存为文件后,编写的程序如下
# coding:utf-8
import re
text=open('肖申克的救赎.html','r')
content=text.read()
print(len(content))
mode=re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>.*?<p class="">.*?'
r'<br>.*?(?P<year>/d+) .*?<span class="rating_num" property="v:average">(?P<score>/s/S)</span>',re.S)
result=re.search(mode,content)
print(result.group('name'))
text.close()
但是运行结果是
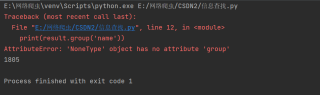
请问问题在哪?







