
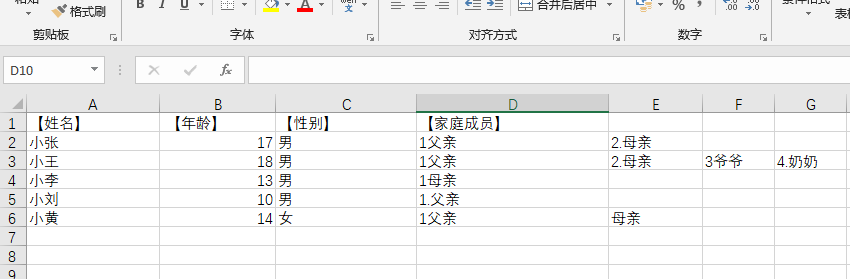
效果如图,txt文本是有规律的很多组的数据,将每组数据写入excle的一行,每组数据最后一项“成员”的内容数量不一定, 就在excle同一行往后一格一个。
import openpyxl
import codecs
from openpyxl.utils import get_column_letter
def txt_to_xlsx(filename,outfile):
fr = codecs.open(filename,'r')
wb = openpyxl.Workbook()
ws = wb.active
ws = wb.create_sheet()
ws.title = 'Sheet1'
row = 0
for line in fr:
row +=1
line = line.strip()
line = line.split('\t')
col = 0
for j in range(len(line)):
col +=1
#print (line[j])
ws.cell(column = col,row = row,value = line[j].format(get_column_letter(col)))
wb.save(outfile)
#读取xlsx内容
def read_xlsx(filename):
#载入文件
wb = openpyxl.load_workbook(filename)
#获取Sheet1工作表
ws = wb.get_sheet_by_name('Sheet1')
#按行读取
for row in ws.rows:
for cell in row:
print (cell.value)
#按列读
for col in ws.columns:
for cell in col:
print (cell.value)
if __name__=='__main__':
inputfileTxt = 'E:\\d.txt'
outfileExcel = 'E:\\b_result.xlsx'
txt_to_xlsx(inputfileTxt,outfileExcel)
read_xlsx(outfileExcel)
这个代码全部稀里糊涂写在第一列了





