关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
1234567!_
2021-10-13 19:02
采纳率: 79.3%
浏览 68
首页
Python
已结题
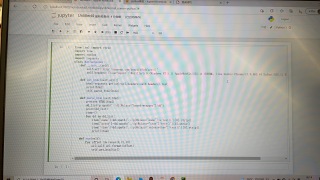
python爬虫运行无结果
python
爬虫
为什么成功运行但是没有结果啊
收起
写回答
好问题
0
提建议
关注问题
微信扫一扫
点击复制链接
分享
邀请回答
编辑
收藏
删除
收藏
举报
1
条回答
默认
最新
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
zkhll
2021-10-13 19:22
关注
你这个目前只写了一个类,并没有调用,肯定是没有结果的
本回答被题主选为最佳回答
, 对您是否有帮助呢?
本回答被专家选为最佳回答
, 对您是否有帮助呢?
本回答被题主和专家选为最佳回答
, 对您是否有帮助呢?
解决
1
无用
1
评论
打赏
微信扫一扫
点击复制链接
分享
举报
评论
按下Enter换行,Ctrl+Enter发表内容
查看更多回答(0条)
向“C知道”追问
报告相同问题?
提交
关注问题
向专家提问
向AI提问
付费问答(悬赏)服务下线公告
◇ 用户帮助中心
◇ 新手如何提问
◇ 奖惩公告
问题事件
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
系统已结题
10月21日
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
已采纳回答
10月13日
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
创建了问题
10月13日





 系统已结题
10月21日
系统已结题
10月21日 已采纳回答
10月13日
创建了问题
10月13日
系统已结题
10月21日
已采纳回答
10月13日
创建了问题
10月13日
已采纳回答
10月13日
创建了问题
10月13日
系统已结题
10月21日
已采纳回答
10月13日
创建了问题
10月13日