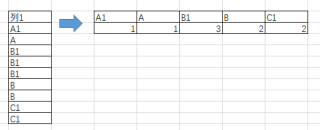
我想用一句SQL语句,让如下图所示的列1,根据内容生成内容计数的列。
我的写法是
SELECT count(列1=“A”)as A, count(列1=“B1”)as B1, count(列1=“B”)as B, count(列1=“C1”)as C1 FROM 表
但是这样不对,出来的计数都是1 .
我又试过
SELECT count(列1)=“A” as A, count(列1)=“B1” as B1, count(列1)=“B” as B, count(列1)=“C1” as C1 FROM 表
也不对,出来的计数都是0 ,请问我应该怎么写