
问题:用基于模型强化学习调节控制系统的三个比例系数,agent采用DDPG算法,agent的动作输出设置为3×1的矩阵,但是仿真结果只显示1×1,无法直接控制三个比例系数,程序和simulink图如下所示,请问如何解决呢?
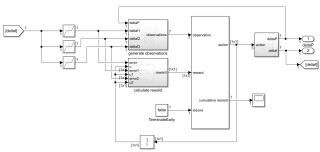
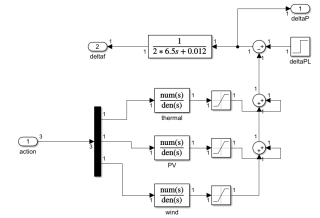
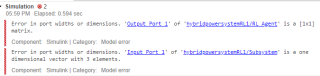
#代码
%% SET UP ENV自定义环境模型
%create the action info
numAct = 3;
actionInfo = rlNumericSpec([numAct 1],...
'LowerLimit',[-Inf -Inf -Inf]',...
'UpperLimit',[-Inf -Inf -Inf]');
actionInfo.Name = 'action';
%Create the observation info
numObs = 7;
observationInfo = rlNumericSpec([numObs 1],...
'LowerLimit',-Inf,...
'UpperLimit',Inf);
observationInfo.Name = 'observation';
%Environment
mdl = 'hybridpowersystemRL1';
open_system(mdl);
env = rlSimulinkEnv(mdl,[mdl '/RL Agent'],observationInfo,actionInfo);
%%这样就会在simulink模型文件中绑定agent模块了,接下来就是设置agent参数
% %
numObs = observationInfo.Dimension(1);
%% 设置仿真时间Tf和智能体采样时间Ts
Ts = 0.02;
Tf = 25;
%为复现结果,固定随机生成器种子
rng(0)
%% 初始化agent CREATE DDPG NETWORKS
%定义具有两个输入(观测量和动作)和一个输出(价值)的神经网络,
statePath = [
imageInputLayer([numObs 1 1],'Normalization','none','Name',...
'observation')
fullyConnectedLayer(128,'Name','CriticStateFC1')
reluLayer('Name','CriticRelu1')
fullyConnectedLayer(200,'Name','CriticStateFC2')];
actionPath = [
imageInputLayer([numAct 1 1],'Normalization','none','Name','action')
fullyConnectedLayer(200,'Name','CriticActionFC1','BiasLearnRateFactor',0)];
commonPath = [
additionLayer(2,'Name','add')
reluLayer('Name','CriticCommonRelu')
fullyConnectedLayer(1,'Name','CriticOutput')];
% Connect the layer graph
criticNetwork = layerGraph(statePath);
criticNetwork = addLayers(criticNetwork,actionPath);
criticNetwork = addLayers(criticNetwork,commonPath);
criticNetwork = connectLayers(criticNetwork,'CriticStateFC2','add/in1');
criticNetwork = connectLayers(criticNetwork,'CriticActionFC1','add/in2');
%查看网络结构
figure
plot(criticNetwork)
criticOptions = rlRepresentationOptions('LearnRate',1e-03,'GradientThreshold',1);
critic = rlRepresentation(criticNetwork,obsInfo,actInfo,...
'Observation',{'observation'},'Action',{'action'},criticOptions);
% if useGPU
% criticOptions.UseDevice = 'gpu';
% end
%% ACTOR 动作网络结构
%定义一个具有一个输入(状态或观测量)和一个输出(动作)的神经网络,决定采取动作
actorNetwork = [
imageInputLayer([numObs 1 1],'Normalization','none','Name',...
'observation')
fullyConnectedLayer(128,'Name','ActorFC1')
reluLayer('Name','ActorRelu1')
fullyConnectedLayer(200,'Name','ActorFC2')
reluLayer('Name','ActorRelu2')
fullyConnectedLayer(1,'Name','ActorFC3')
tanhLayer('Name','ActorTanh1')
scalingLayer('Name','ActorScaling','Scale',max(actInfo.UpperLimit))];
actorOptions = rlRepresentationOptions('LearnRate',5e-04,'GradientThreshold',1);
actor = rlRepresentation(actorNetwork,obsInfo,actInfo,...
'Observation',{'observation'},'Action',{'ActorScaling'},actorOptions);
%% 设置训练参数
%% DDPG Agent Options
agentOptions = rlDDPGAgentOptions;
agentOptions.SampleTime = Ts;%采样时间
agentOptions.DiscountFactor = 0.99;%折扣因子
agentOptions.MiniBatchSize = 128;
agentOptions.ExperienceBufferLength = 5e5;
agentOptions.TargetSmoothFactor = 1e-3;
agentOptions.NoiseOptions.MeanAttractionConstant = 5;%随机化探索
agentOptions.NoiseOptions.Variance = 0.5;
agentOptions.NoiseOptions.VarianceDecayRate = 1e-5;
%% Training Options
maxepisodes = 2000;
maxsteps = ceil(Tf/Ts);
trainingOptions = rlTrainingOptions(...
'MaxEpisodes',maxepisodes,...
'MaxStepsPerEpisode',maxsteps,...
'ScoreAveragingWindowLength',5,...
'Verbose',false,...
'Plots','training-progress',...
'StopTrainingCriteria','AverageReward',...
'StopTrainingValue',400,...
'SaveAgentCriteria','EpisodeReward',...
'SaveAgentValue',400);
% trainingOptions = rlTrainingOptions;
% trainingOptions.MaxEpisodes =1000;
% trainingOptions.MaxStepsPerEpisode = Tf/Ts;
% trainingOptions.ScoreAveragingWindowLength = 1000;
% trainingOptions.StopTrainingCriteria = 'AverageReward';
% trainingOptions.StopTrainingValue = 110;
% trainingOptions.SaveAgentCriteria = 'EpisodeReward';
% trainingOptions.SaveAgentValue = 150;
% trainingOptions.Plots = 'training-progress';
% trainingOptions.Verbose = true;
% if useParallel
% trainingOptions.Parallelization = 'async';%异步
% trainingOptions.ParallelizationOptions.StepsUntilDataIsSent = 32;%每32个时间步发送给代理;
% end
%% 并行学习设置
trainingOptions.UseParallel = true;
trainingOptions.ParallelizationOptions.Mode = "async";
trainingOptions.ParallelizationOptions.DataToSendFromWorkers = "Experiences";
trainingOptions.ParallelizationOptions.StepsUntilDataIsSent = -1;
%% 训练
agent = rlDDPGAgent(actor,critic,agentOptions);
trainingStats = train(agent,env,trainingOptions);
%% SAVE AGENT
reset(agent); % Clears the experience buffer
curDir = pwd;
saveDir = 'savedAgents';
cd(saveDir)
save(['trainedAgent' datestr(now,'mm_DD_YYYY_HHMM')],'agent');
save(['trainingResults' datestr(now,'mm_DD_YYYY_HHMM')],'trainingResults');
cd(curDir)
%% 结果展示验证训练好的仿真,可以在仿真中对环境和智能体的组合模型仿真
simOptions = rlSimulationOptions('MaxSteps',500);%创建默认选项集
experience = sim(env,agent,simOptions);
totalReward = sum(experience.Reward);
% bdclose(mdl)







