
用python爬虫,代码用xpath总是获取不到内容,希望大家帮我看看这两个网页中所需内容如何定位?
1.想要获取下面网址中的 债券基本信息 ,试了很多xpath的路径都失败了,都是空的_(¦3」∠)_,下面贴出测试用的代码,希望大家能帮我看下xpath那部分为什么不对(倒数第二行),也可能是其他问题o(╥﹏╥)o
import requests
from lxml import html
url = 'http://www.chinamoney.com.cn/chinese/zqjc/?bondDefinedCode=1000040278'
page = requests.Session().get(url)
tree = html.fromstring(page.text)
result = tree.xpath('//tbody//tr//th/text()')
print(result)
2.想要获取下面网址中的一个href属性 (截图中阴影部分,就是查询结果的网址),也试了很多xpath的路径也都失败了,不知道@href前应该写什么。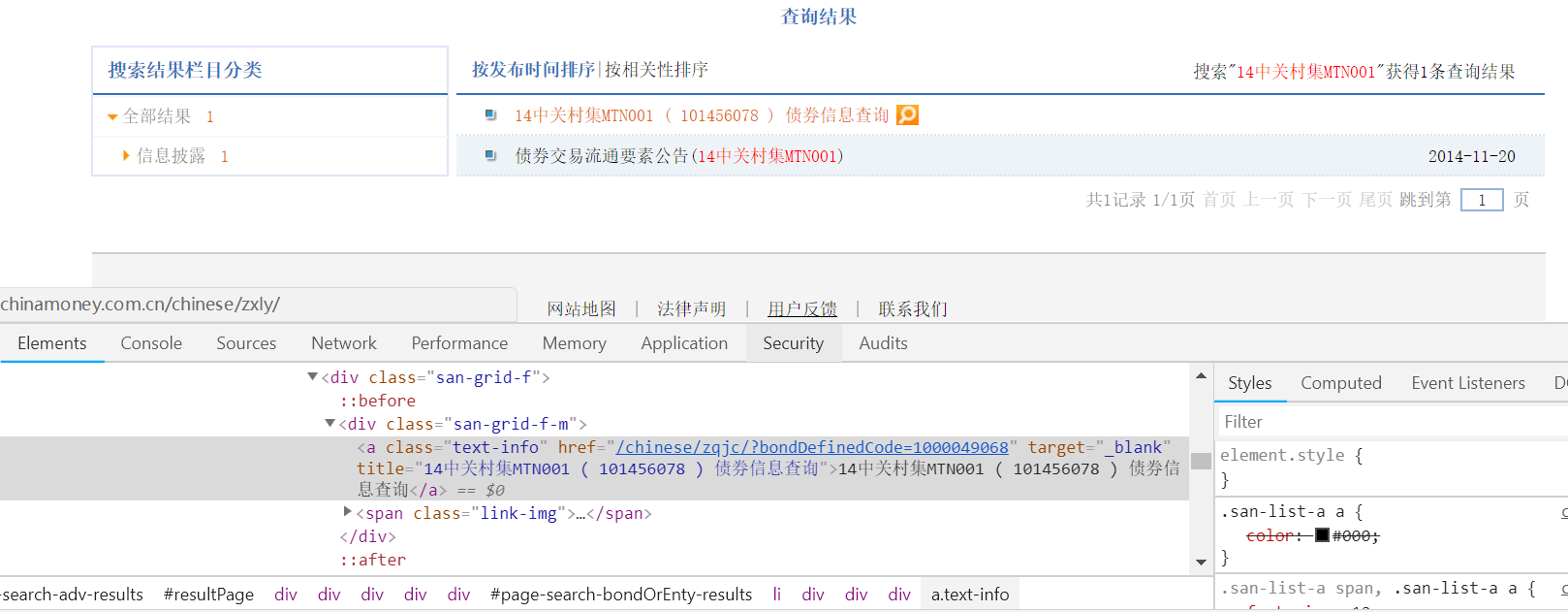
url = 'http://www.chinamoney.com.cn/chinese/qwjsn/?searchValue=14中关村集MTN001'
第一次提问,有什么不合适的希望谅解,工作需要,时间比较急切,麻烦大家了。━((*′д`)爻(′д`*))━!!!!




