以下回答参考 皆我百晓生、券券喵儿 等免费微信小程序相关内容作答,并由本人整理回复。
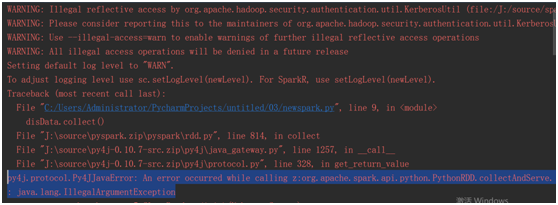
从您提供的信息来看,问题可能出在Spark与Python交互时的异常处理方面。根据您的描述,您尝试在PySpark环境中使用sc.parallelize()方法来并行化数据,并且遇到了IllegalArgumentException错误。
首先,请确保您安装了正确的版本的PySpark和Python。对于PySpark,您可以参考以下命令来安装:
pip install pyspark
pip install py4j
然后,在您的项目中,可以按照以下步骤设置环境变量以确保正确地将PySpark和Python连接起来:
-
打开终端或命令提示符。
-
输入以下命令以创建环境变量(如果尚未创建):
export SPARK_HOME=<路径到PySpark安装目录>
export PYSPARK_PYTHON=<路径到Python解释器>
确保替换 <路径到PySpark安装目录> 和 <路径到Python解释器> 为实际的路径。
-
检查Python解释器是否已正确添加到系统搜索路径中。如果您正在使用Anaconda或其他虚拟环境,请确保在~/.bashrc文件中包含以下内容:
export PATH=$PATH:$SPARK_HOME/bin
如果您没有找到这些环境变量,请通过编辑.bashrc文件或~/.bash_profile文件手动添加它们。
-
接下来,打开一个新的Python脚本,例如test_spark.py,并在其中测试sc.parallelize()方法:
import pyspark
from pyspark.sql import SparkSession
conf = SparkConf().setAppName('test_spark').setMaster('local[*]')
spark = SparkSession.builder.config(conf=conf).getOrCreate()
data = [1, 2, 3, 4, 5]
result = spark.parallelize(data)
print(result.collect())
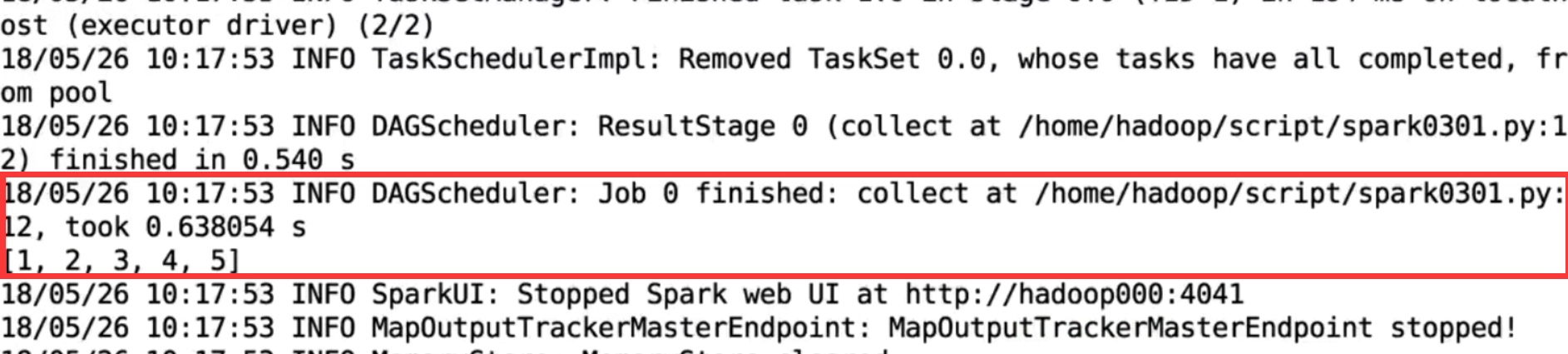
运行此脚本后,应看到数据被成功并行化并打印出来。
-
尝试再次执行您的原始代码片段。这应该解决您遇到的异常。
希望以上信息对您有所帮助!如果您还有其他问题,请随时提问。