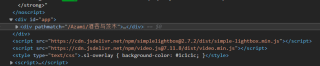
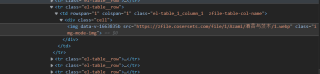



用的beautifulsoap,其他网站都能爬取,但这个网站不行。
这个网站用的是webp图片,标签依旧是img,可以直接查看到图片的地址,但是爬取得到的网站解析出来缺失了关键内容。
换了htmlparser,html5lib都不行。
请问能否有人能解答为什么吗?

用的beautifulsoap,其他网站都能爬取,但这个网站不行。
这个网站用的是webp图片,标签依旧是img,可以直接查看到图片的地址,但是爬取得到的网站解析出来缺失了关键内容。
换了htmlparser,html5lib都不行。
请问能否有人能解答为什么吗?
 分享
分享
题主是用requests获取网页内容?requests只能获取源代码,ajax动态生成的需要找到接口,requests请求接口获取数据。如果不是ajax动态生成,源代码里面又找不到,那么数据可能是放在js文件里面,需要找到数据文件后requests请求
要么的得用selenium来解析相关js脚本后获取数据
分享 系统已结题
10月29日
系统已结题
10月29日 已采纳回答
10月21日
修改了问题
10月21日
修改了问题
10月21日
已采纳回答
10月21日
修改了问题
10月21日
修改了问题
10月21日

