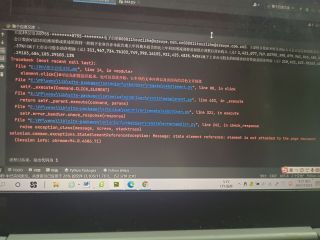
代码如下,报错为第14行:
from selenium import webdriver
import time
global pages#全局变量。如果可以的话希望能换个地方呆着。全局变量的写法,先后顺序
pages=set()#一万个页面的储存体
driver = webdriver.Chrome()
driver.get('https://snail.baidu.com/ndyanbao/browse/index#/search')
#print(driver.current_url)#打印当前的url
time.sleep(5)
i=0
while i < 1000:
i=i+1
elements = driver.find_elements_by_class_name('report-title') # 第一层的标题的按钮
for element in elements:
element.click()#可以先把链接存起来,也可以直接开始:它本身的文本内容以及页面内的其他文章链接
time.sleep(30)
hand = driver.window_handles # 获取当前的所有句柄
driver.switch_to.window(hand[1]) # 转换窗口至最高的句柄
time.sleep(30)
LD=driver.find_elements_by_class_name('btn login-btn')#登录观看
if LD is True:
LD = driver.find_elements_by_class_name('btn login-btn') # 登录观看
ld=LD[0]
ld.click()
yhm = driver.find_elements_by_css_selector('#TANGRAM__PSP_11__footerULoginBtn') # 用户名登录
yhmd = yhm[0]
yhmd.click()
yh = driver.find_elements_by_css_selector('#TANGRAM__PSP_11__userName') # 用户名
yh = yh[0]
yh.send_keys('用户名')
mm = driver.find_elements_by_css_selector('#TANGRAM__PSP_11__password') # 密码
mm = mm[0]
mm.send_keys('密码')
dl = driver.find_elements_by_css_selector('#TANGRAM__PSP_11__submit') # 点击登录按钮
dl = dl[0]
dl.click()
time.sleep(10)
xt = driver.find_elements_by_class_name('reader-word-layer') # 爬取文章内容#加入百度文库4的代码
xt2 = [str(i.text) for i in xt]
print(''.join(xt2)) # 后期改为TXT。join列表方法
wz = driver.current_url # 当前的url
pages.add(wz) # 将第一层的10000个页面全部存进pages中
time.sleep(5)
# driver.quit()
else:
xt = driver.find_elements_by_class_name('reader-word-layer') # 爬取文章内容#加入百度文库4的代码
xt2 = [str(i.text) for i in xt]
print(''.join(xt2))#后期改为TXT。join列表方法
wz = driver.current_url # 当前的url
pages.add(wz)#将第一层的10000个页面全部存进pages中
time.sleep(5)
#driver.quit()
nps= driver.find_elements_by_class_name('el-icon.el-icon-arrow-right') #下一页按钮
for np in nps:
nps.click()
else:
for page in pages:#第一层以及后边几层的网址
driver.get('page')
qts=driver.find_elements_by_class_name('doc-title')#当前页面中含有的的其他文本的按钮.准备进入第二层
for qt in qts:#当前页面内可操作的文本标题
qt.click()#之后要在其他页面上重复操作。进入第二层
hand = driver.window_handles # 获取当前的所有句柄
driver.switch_to.window(hand[1]) # 转换窗口至最高的句柄
ht = driver.current_url#获得他们的URL
time.sleep(30)
LD = driver.find_elements_by_class_name('btn login-btn') # 登录观看
if LD is True:
LD = driver.find_elements_by_class_name('btn login-btn') # 登录观看
ld = LD[0]
ld.click()
yhm = driver.find_elements_by_css_selector('#TANGRAM__PSP_11__footerULoginBtn') # 用户名登录
yhmd = yhm[0]
yhmd.click()
yh = driver.find_elements_by_css_selector('#TANGRAM__PSP_11__userName') # 用户名
yh = yh[0]
yh.send_keys('用户名')
mm = driver.find_elements_by_css_selector('#TANGRAM__PSP_11__password') # 密码
mm = mm[0]
mm.send_keys('密码')
dl = driver.find_elements_by_css_selector('#TANGRAM__PSP_11__submit') # 点击登录按钮
dl = dl[0]
dl.click()
time.sleep(10)
xt = driver.find_elements_by_class_name('reader-word-layer') # 爬取文章内容#加入百度文库4的代码
xt2 = [str(i.text) for i in xt]
print(''.join(xt2)) # 后期改为TXT。join列表方法
wz = driver.current_url # 当前的url
pages.add(wz) # 将第一层的10000个页面全部存进pages中
time.sleep(5)
# driver.quit()
else:
xt = driver.find_elements_by_class_name('reader-word-layer') # 爬取文章内容.#加入百度文库4的代码
xt2 = [str(i.text) for i in xt]
print(''.join(xt2))
if ht not in pages:
pages.add(ht)
driver.quit()
报错: