
【问题描述】下面的描述字符串的方法称为速记符:
1."a-d" : 代表ASCII码在a和b之间的所有字符构成的连续字符串。其中必有a<b。
2."a-b-c" : 代表ASCII码在a和b, 再到c之间的所有字符构成的连续字符串。其中必有a<b<c。
例如:"a-c"代表字符串"abc","a-z"代表字符串"abcdefghhijklmnopqrstuvwxyz","a-c-g"代表字符串"abcdefg",等等。
在字符串开始和结尾处的'-'不做处理。 编写函数expand(s1),将字符串s1中的速记符号加以扩展形成等价的完整串.允许处理大小写字母和数字,并可以处理诸如a-b-c与a-z0-9与-a-z等情况.
编写程序,使用函数expand,将输入的字符串s1,进行处理,将结果输出.正确安排好前导和尾随的-.
【输入形式】控制台输入一行,即为s1的内容.可以含有空格,制表符,换行符.
【输出形式】控制台输出变换后的s1.
【样例输入】toooold-f0-8 A-F
【样例输出】tooooldef012345678 ABCDEF
【样例说明】输出对输入中的d-f,0-8,A-F进行了扩展.

python难题,大家帮我看看

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

3条回答 默认 最新
 辉煌仪奇 2021-10-24 19:10关注
辉煌仪奇 2021-10-24 19:10关注有帮助请点击右上角采纳,有问题继续交流,你的采纳是对我回答的最大的肯定和动力
s = 'tld-f0-8 A-F' import re res = re.findall('\w{1}-\w{1}', s) for m in res: st = m.split('-')[0] ed = m.split('-')[1] if st.isdigit() and ed.isdigit(): v = ''.join(list(map(str, range(int(st), int(ed) + 1)))) else: v = ''.join([chr(x) for x in range(ord(st), ord(ed) + 1)]) s = s.replace(m, v) print(s)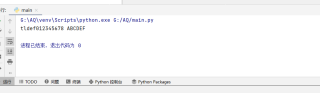 本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
- 2021-01-20 02:17我和我的女朋友因为python而相识,同时...看看我女朋友的头发最近掉的厉害,作为一个男人我必须扛起责任!于是我拦下这活,并且给我女朋友说道:等我学会了python多线程我讲给你听! 原创文章 45获赞 605访问量 5万+
- 2024-11-04 13:36首先,我们来看如何编写Python代码来求解100以内的质数。质数是只能被1和其本身整除的自然数,且大于1的整数。在编程中,我们通常采用一种称为“试除法”的方法,也即从2开始,逐步检查一个数是否能够被比它小的数...
- 2025-05-25 20:10综合来看,这个“Python源码-python 玛丽冒险 游戏源码.zip”文件,不仅是一个游戏开发项目,更是Python语言多方面应用的体现。它可能包含了游戏设计、人工智能、数据分析以及可能的网络交互等多个层面的知识点,...
- 2025-11-17 01:05从工具资源来看,Python开发者可以利用的工具有很多,包括但不限于集成开发环境(IDE)、代码调试工具、性能分析工具、版本控制系统等。这些工具极大地提高了开发效率,使开发者能够更加专注于代码的编写与优化,而...
- 2025-11-13 07:14开发者通过编写Python爬虫脚本,解决了这一难题。在文章中,作者详细介绍了使用抓包工具如Charles和Fiddler(FD)来分析微信服务号的网络请求,这对于理解如何模拟请求来抢号至关重要。通过抓取请求数据,开发者能够...
- 2021-04-07 01:09首先,我们来看看Python在AdventOfCode2020中所展现的优势。Python以其简洁的语法和丰富的库支持,成为了许多开发者首选的编程语言。对于算法和数据结构的处理,Python提供了诸如numpy、pandas等高效工具,使得处理...
- 2025-08-08 20:01而从江苏大学选修课Python作业的标签来看,这门课程受到了广泛的关注,成为不少学生提升编程技能的首选。 需要注意的是,虽然Python的入门门槛相对较低,但是要想真正掌握这门语言,学生需要付出大量的时间和精力。...
- 2025-08-24 23:27从给出的信息来看,我们有一个关于Python编程语言的资源压缩包,名为"Python100-master (2).zip"。标题中的"(5)"可能是文件的版本号或序号,但由于文件列表中只提供了"(2)"版本,我们将会针对这个版本进行讨论。由于...
- 2025-06-23 19:57由于文件是压缩状态的,我们无法直接窥探其内部结构,但从文件名“Python100-master (2).zip”和“Python100-master (3).zip”来看,它们可能是一个系列或版本,表明这是一个更新或者修订后的文件。这暗示了资源的...
- 2021-04-14 21:02首先,我们来看广度优先搜索(BFS)。BFS是一种用于遍历或搜索树或图的算法,它按照节点的层次进行探索。在八数码难题中,BFS通常通过维护一个队列来存储所有可能的棋盘状态,从初始状态开始,不断扩展出新的状态,...
- 没有解决我的问题, 去提问

问题事件
 已结题
(查看结题原因) 10月24日
已结题
(查看结题原因) 10月24日-
已采纳回答
10月24日
-
修改了问题
10月24日
-
创建了问题
10月24日