
需要从TXT文件中提取以下三个字段信息,正则表达式应该怎么写比较好呢?
'gender': {'type': 'male', 'probability': 1}, 'emotion': {'type': 'sad', 'probability': 0.58}}]}}, '#', 'G:\Chunyu\中1.jpg'
源数据格式是这样的:
({'error_code': 0, 'error_msg': 'SUCCESS', 'log_id': 8494848494947, 'timestamp': 1635127822, 'cached': 0, 'result': {'face_num': 1, 'face_list': [{'face_token': 'f97aca8cf9d44434e3f1e0f0a4c8a871', 'location': {'left': 28.57, 'top': 52.3, 'width': 93, 'height': 91, 'rotation': -1}, 'face_probability': 1, 'angle': {'yaw': -6.63, 'pitch': 7.59, 'roll': -2.64}, 'age': 35, 'beauty': 52.53, 'gender': {'type': 'male', 'probability': 1}, 'expression': {'type': 'none', 'probability': 1}, 'face_shape': {'type': 'square', 'probability': 0.45},**** 'glasses': {'type': 'common', 'probability': 1}, 'emotion': {'type': 'sad', 'probability': 0.58}}]}}, '#', 'G:\Chunyu\中1.jpg'****
这样子是一条,一共有8000+条,需要提取出加粗的部分
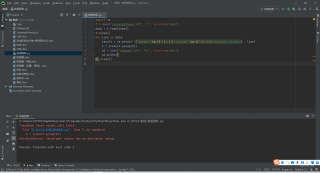
这是现在的情况,求指教






