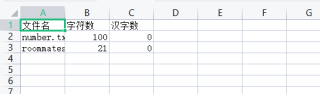
最终表格是
文件名 字符数 汉字数
txt1 100 20
txt2 523 214
txt3 214 30
……
……
步骤是
1、建一个tj表
2. 循环打开文件夹下txt
统计 txt1的文件名,字符数,汉字数
获取以上内容
打开tj表,
追加写入txt1的内容(在循环内不断追加)
请问如何实现呢?感谢各位大神

大神们,请问如何统计文件夹下的所有txt的字符数和汉字数,并统计到表格中

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

3条回答 默认 最新
 辉煌仪奇 2021-10-27 11:30关注
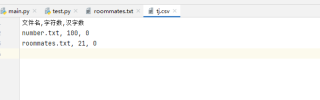
辉煌仪奇 2021-10-27 11:30关注import os import re with open('tj.csv', 'w+') as tj: tj.write('文件名,字符数,汉字数\n') for i in os.listdir(r'.'): hanz = 0 zifu = 0 if 'txt' in i: with open(i, 'a+') as f: txt = f.read() hanz += len(re.findall('[\u4e00-\u9fa5]', txt)) zifu += len(re.findall('[A-Za-z0-9]', txt)) tj.write(f'{i}, {zifu}, {hanz}\n')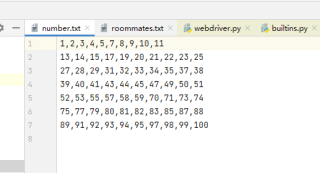
 本回答被题主选为最佳回答 , 对您是否有帮助呢?评论 打赏解决 1无用举报 分享
本回答被题主选为最佳回答 , 对您是否有帮助呢?评论 打赏解决 1无用举报 分享
- 2024-08-02 22:04大雨淅淅的博客 本文为Python编程学习指南,从零基础入门到进阶实战,全面介绍了Python的核心知识和学习路径。文章首先阐述了Python的简洁语法、广泛应用和强大社区等优势,然后系统讲解了基础语法、数据结构、函数模块、面向对象...
- 2024-07-16 08:47猰貐的新时代的博客 NER(中文实体命名识别)关键字: 中文命名实体识别 NER BILSTM CRF IDCNN BERT摘要:对中文命名实体识别一直处于知道却未曾真正实践过的状态,此次主要是想了解和实践一些主流的中文命名实体识别的神经网络算法。...
- 2020-12-06 00:49weixin_39643338的博客 /usr/bin/pythonimport threadingimport jsonimport timefrom elasticsearch import Elasticsearchfrom elasticsearch import helpersimport osimport sysimport argparsehost_list = [{"host":"1.58.55.11","port.....
- 2025-01-24 10:31莲华君的博客 想用Python写API快到飞起?FastAPI就是你的“代码瑞士军刀”!这本书不讲玄学,只教真功夫——从零搭建高性能API,到微服务、分布式事务、熔断限流,连异步编程都能玩成魔法! 小白也能变大神:路由、依赖注入、...
- 2025-10-04 14:16森林里的一只猫的博客 Flet最核心的价值,在于它让Python新手“不用等学会所有技术再动手”——你不需要掌握前端、不需要懂服务器配置、不需要学习新的编程语言,只要会Python基础,就能在1小时内开发出能在电脑、手机、网页上运行的APP。...
- 2023-11-09 09:53amingMM的博客 https://www.python.org/downloads/ ...文件 打开 写入模式 ‘w’ ...数据类型 String 字符串 字面量 字符去除 逆序数字 格式化 切片 去空格 参数类型 字符 大小写 Python 标准库模块 Standar
- 2021-12-28 14:27测试架构师北凡的博客 【第一节:python函数(def)】 义函数 函数的定义 函数的分类 函数的创建方法 函数的返回return 函数的定义 将一件事情的步骤封装在一起并得到最终结果 函数名代表了这个函数要做的事情 函数体是实现函数...
- 2020-04-28 23:53weixin_47278555的博客 这里写自定义目录标题Python小白逆袭大神七日打卡营全纪录新的改变功能快捷键合理的创建标题,有助于目录的生成如何改变文本的样式插入链接与图片如何插入一段漂亮的代码片生成一个适合你的列表创建一个表格设定内容...
- 2401_84265592的博客 兄弟们,你们心心念念的python全栈系列4-4系类就出完了,其实python全栈系列我本来是准备写一个整个系列的,完全不止现在这么4篇幅文章,但是这样又太过于耗时间,细心的小伙伴应该就发现了,凡哥把python全栈接口...
- 2020-05-01 18:37汤半泛的博客 本文描述了作者在参加百度Python小白逆袭大神课程一些亲身经历,从开始的半信半疑,到最后坚定的革命信念,给没有参加过百度课程的同学一点参考,文中有高质量的数据分析、pyecharts动态图,深度学习相关代码分享,...
- 没有解决我的问题, 去提问

问题事件
 系统已结题
11月4日
系统已结题
11月4日 已采纳回答
10月27日
已采纳回答
10月27日-
创建了问题
10月26日