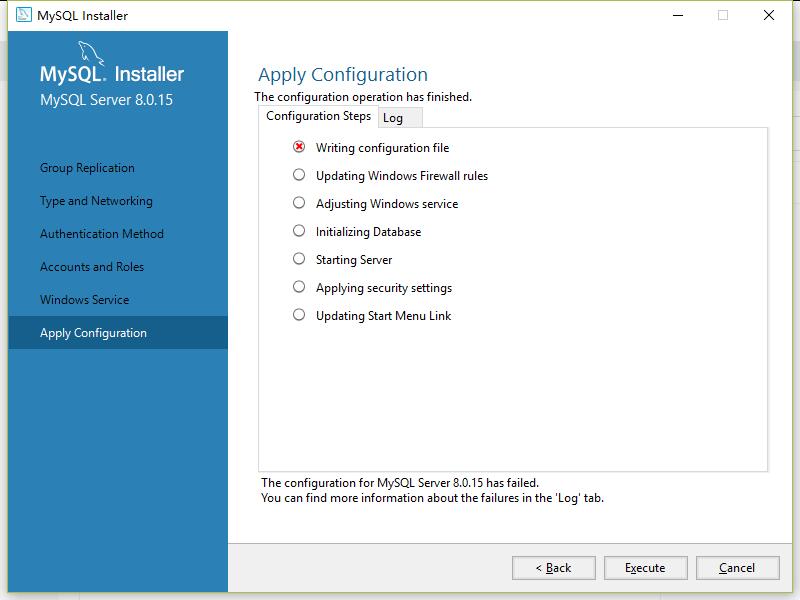
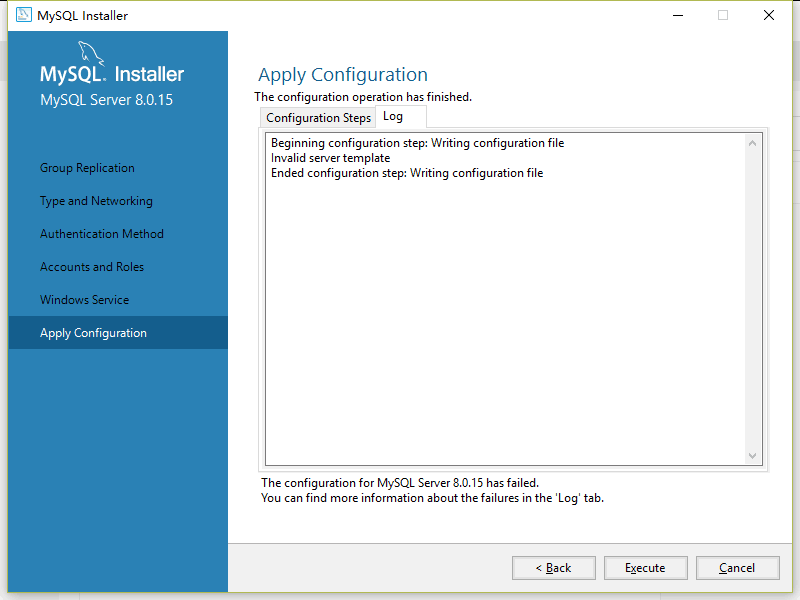
重新安装还是不行

MySQL apply configuration时出现的问题不知道怎么处理,哪位大佬能帮忙解决下啊?

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

1条回答 默认 最新
 树莓大王 2023-03-15 08:12关注
树莓大王 2023-03-15 08:12关注根据您提供的截图显示,您遇到了MySQL apply配置时的错误。这个错误可能是由于MySQL配置文件发生了一些错误或者损坏引起的。我建议您可以尝试以下几个步骤来解决这个问题:
1.检查MySQL配置文件的路径是否正确,路径不正确也会引起这个错误。
2.查看MySQL配置文件是否存在,如果不存在,可以重新创建一个空的MySQL配置文件。
3.检查MySQL的权限,确保MySQL的用户可以访问到MySQL配置文件。
4.可以尝试使用mysqld --initialize创建新的数据目录和一些默认配置文件。
如果以上方法都不能解决问题,还存在其他问题,可以提供更多的错误信息,便于更好地解决问题。
解决 无用评论 打赏举报 分享
- 2019-04-03 16:47
- 2021-11-25 20:09Sammirya的博客 今天终于把mysql安装上了,以前安装了几次都没有装上,我已经麻了,但是今天又重新安装的时候,错了很多次,查了很多次资料,终于安装上了!!!!!!!! 在这里分享一下我的解决方法 安装第三步出错 1、首先我们...
- 2026-03-24 13:09allway2的博客 一个 GITD 由两部分组成的,分别是 source_id 和 transaction_id,结构为 GTID=source_id:transaction_id,其中 source_id 就是执行事务的主库的 server-uuid 值,server-uuid 值是在 mysql 服务首次启动生成的,...
- 2023-12-02 20:26geocodingcoder的博客 大家好,我是Leo哥,前几天一个在大学的粉丝跟我说:Leo哥,我们最近要搞那个Java期末作业,要求是通过Javaweb知识点,使用JDBC,MySQL,JSP,Servlet等技术实现一个登录和注册功能,能不能出一期教程啊,老师啥也不...
- 2023-09-04 20:44娱乐先生。的博客 他的解决语句混乱不堪)mysql8新版本发布,安装后出现2059错误,因为安装时选择了强加密规则caching_sha2_password,与之前的mysql5.7的mysql_native_password规则不同,navicate驱动目前不支持新加密规则。...
- 2023-08-13 02:13云边散步的博客 想单纯看图片求快速安装进行安装就看4,然后mysql8和mysql5安装过程只多了2.5.3通过我这篇保姆级的教程你将把mysql8和mysql5的安装轻松安装拿下,如果你在安装的过程中遇到什么问题,欢迎您在评论区指出或者私信我,...
- 2022-05-23 18:35ZePingPingZe的博客 ① 如果数据库发生了宕机或者意外中断等故障,能尽快恢复数据库的可用性,尽可能的减少停机时间,保证业务不会因为数据库的故障而中断。 ② 用作备份、只读等功能的【非主节点】的数据应该和主节点的数据实时或者...
- 2024-05-01 17:012401_84140332的博客 C ~/app/ 配置环境SPARK_HOME source ~./bash_profile 运行 spark-shell --master local[2] at org.apache.spark.repl.SparkILoop$$anonfun$initializeSpark$1.apply(SparkILoop.scala:37) at org.apache.spark....
- 2021-01-19 21:39Cass Lin的博客 之前在《打造扛的住的MySQL》和《高性能MySQL架构设计》两门实战课程中,已经为大家讲解了很多种MySQL高可用架构的设计和实现方法,包括MHA,MMM以及keepalived等方式来实现MySQL的高可用,现在MySQL5.7.17版本中...
- 2018-11-28 13:31肖朋伟的博客 (6)勾选 SQl 下的 MySQL,MyBatis 依赖: (根据自己的项目选择,后面可加) (7)选择好项目的位置,点击【Finish】: (7)如果是第一次配置 Spring Boot 的话可能需要等待一会儿 IDEA 下载相应的 依赖...
- 没有解决我的问题, 去提问
