

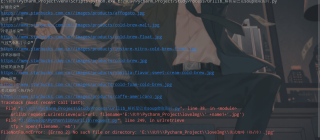
这里的最后一个图片为什么下载不到本地,就最后一个图片有问题,求解
import requests
import urllib.request
from bs4 import BeautifulSoup
url = 'https://www.starbucks.com.cn/menu/'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
}
wb_data=requests.get(url=url,headers=headers)
response=urllib.request.urlopen(url)
content = response.read().decode('utf-8')
soup = BeautifulSoup(content, 'lxml')
#//url[@class="grid padded-3 product"]//strong/text()
#name_list = soup.select('ul[class="grid padded-3 product"]')
#imgs=soup.find_all('div')
imgs= soup.select('ul[class="grid padded-3 product"] div')
name_list=soup.select('ul[class="grid padded-3 product"] strong')
for i in range(len(name_list)):
name = name_list[i]
name1 = name.get_text()
url=imgs[i].get("style")
url = url[23:len(url) - 2]
url = 'https://www.starbucks.com.cn/' + url
print(name1)
print(url)
urllib.request.urlretrieve(url=url, filename='E:\软件\Pycharm_Project\loveImg\\' +name1+'.jpg')
print('---download---')







