关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
荷锄芳草间
2021-10-30 14:14
采纳率: 66.7%
浏览 42
首页
有问必答
已结题
如果要获取<div>标签下的文本内容该怎么做呢?(用xpath,bs4,re中的一个都行)
有问必答
python
爬虫
如果要获取
标签下的文本内容该怎么做呢?(用xpath,bs4,re中的一个都行)
收起
写回答
好问题
0
提建议
关注问题
微信扫一扫
点击复制链接
分享
邀请回答
编辑
收藏
删除
收藏
举报
4
条回答
默认
最新
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
爱音斯坦牛
优质创作者: 编程框架技术领域
2022-10-14 12:31
关注
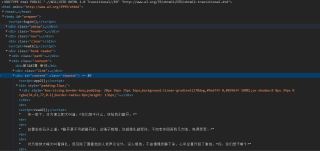
鼠标右键复制xpath,然后在python中/text()或者.text获取文本内容,如图:
有帮助的话采纳一下哦!
本回答被题主选为最佳回答
, 对您是否有帮助呢?
本回答被专家选为最佳回答
, 对您是否有帮助呢?
本回答被题主和专家选为最佳回答
, 对您是否有帮助呢?
解决
无用
评论
打赏
微信扫一扫
点击复制链接
分享
举报
编辑记录
评论
按下Enter换行,Ctrl+Enter发表内容
查看更多回答(3条)
向“C知道”追问
报告相同问题?
提交
关注问题
HTML网页解析之
Xpath
,
bs4
及re
2020-04-23 22:35
尘归尘-北尘的博客
1.常用工具介绍
Xpath
:
XPath
即为XML路径语言(XML Path Language),它是一...re:正则表达式是一种通用的字符串表达框架,用来基于匹配模式测试字符串内的模式,替换
文本
和查找
文本
。 2.各工具详解 2.1
Xpath
XPa...
爬虫学习二:
bs4
xpath
re
2021-02-04 09:29
浩波的笔记的博客
2.1 Beautiful Soup库入门 目标: 2.1.1 Beautiful Soup库的基本元素 2.1.2 基于
bs4
库的HTML
内容
遍历方法 2.1.3 基于
bs4
库的HTML
内容
的查找方法 2.1.4 实战:
中
国大学排名定向爬取 ...2.3 学习正则表达式re
Python
成长之路——regex,
bs4
,
xpath
,jsonpath的使用
2019-04-19 12:36
有所为有所不为的博客
[aoe] [a-w] 匹配集合
中
任意
一个
字符 \d 数字[0-9] \D 非数字 \w 数字、字母、下划线、
中
文 \W 非\w \s 所有的空白字符 \S 非空白 数量修饰类型 说明 *...
Python
爬虫编程实践--re bs及
xpath
2020-04-23 23:31
迷糊小财迷的博客
Beautiful Soup 是
一个
HTML/XML 的解析器,主要用于解析和提取 HTML/XML 数据。 它基于HTML DOM 的,会载入整个文档,解析整个DOM树,因此时间和内存开销都会大很多,所以性能要低于lxml。 BeautifulSoup 用来解析 ...
python
爬虫训练11:正则表达式,
bs4
,
xpath
抓取网站数据对比
2022-07-04 19:29
<编程路上>的博客
无论哪种,先看源代码: 本次对比是分别抓取排行榜书名,作者和简介。 正则表达式: 正则表达式其实是最简单的,熟练的话...在
BS4
中
,通过
标签
名和
标签
属性可以提取出想要的
内容
。
xpath
:
XPath
的选择功能十分强大
python
爬虫数据采集使用的三种匹配方式:正则re,
xpath
,beautifulsoup4
2019-03-09 11:22
pray~的博客
一般情况下三种方式都是可以匹配到结果的,只是复杂程度不一致,根据情况进行选择re/
xpath
/
bs4
先进行简单的比较:一、正则re的使用二、lxml三、
bs4
的使用 先进行简单的比较: 抓取工具 速度 使用难度 安装 ...
正则,
bs4
,
xpath
的使用方法
2018-04-27 17:54
穆洛玄的博客
数据匹配的三
中
方法,
bs4
,
xpath
,正则第一种:正则(先导入re库)分为三种查找方法式:re.math(),re.search(),re.findall()re.math():是从所要匹配的字符串的起始位置开始匹配且只值输出
一个
值,一般不用因为太耗时了...
正则
bs4
xpath
的数据请求方式和
获取
数据方式
2018-08-01 19:35
sklsxy的博客
(一)BeautifulSoup 从本心来说,我更喜欢用BeautifulSoup。因为它更符合直观语义特性,find()和find_all()函数已经基本上足够提取出任何的信息,对于身份证号、QQ号等特征特别明显的数据,顶多再加上
一个
正则...
Python
----
Python
爬虫(re、
bs4
、pyquery、
xpath
、json的使用)
2025-01-02 20:11
蹦蹦跳跳真可爱598的博客
Python
----
Python
爬虫(re、
bs4
、pyquery、
xpath
、json的使用)
爬虫之提取数据
xpath
/BeautifulSoup/css/正则(re)的基本使用
2019-04-13 19:08
Java川的博客
1.
xpath
方法 与lxml的etree配合使用 2.BeautifulSoup 3.正则 1.
xpath
使用参考菜鸟教程: http://www.runoob.com/?s=
xpath
2.BeautifulSoup基本使用案例: #-*encoding:utf-8 *- #BeautifulSoup 基本使用案例 # 1....
没有解决我的问题,
去提问
向专家提问
向AI提问
付费问答(悬赏)服务下线公告
◇ 用户帮助中心
◇ 新手如何提问
◇ 奖惩公告
问题事件
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
系统已结题
10月22日
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
已采纳回答
10月14日
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
创建了问题
10月30日

 分享
分享
 关注
关注 分享
分享 系统已结题
10月22日
系统已结题
10月22日 已采纳回答
10月14日
创建了问题
10月30日
已采纳回答
10月14日
创建了问题
10月30日

