
目前在学习目标检测识别的方向。
自己参考了一些论文 对原版的SSD进行了一些改动工作
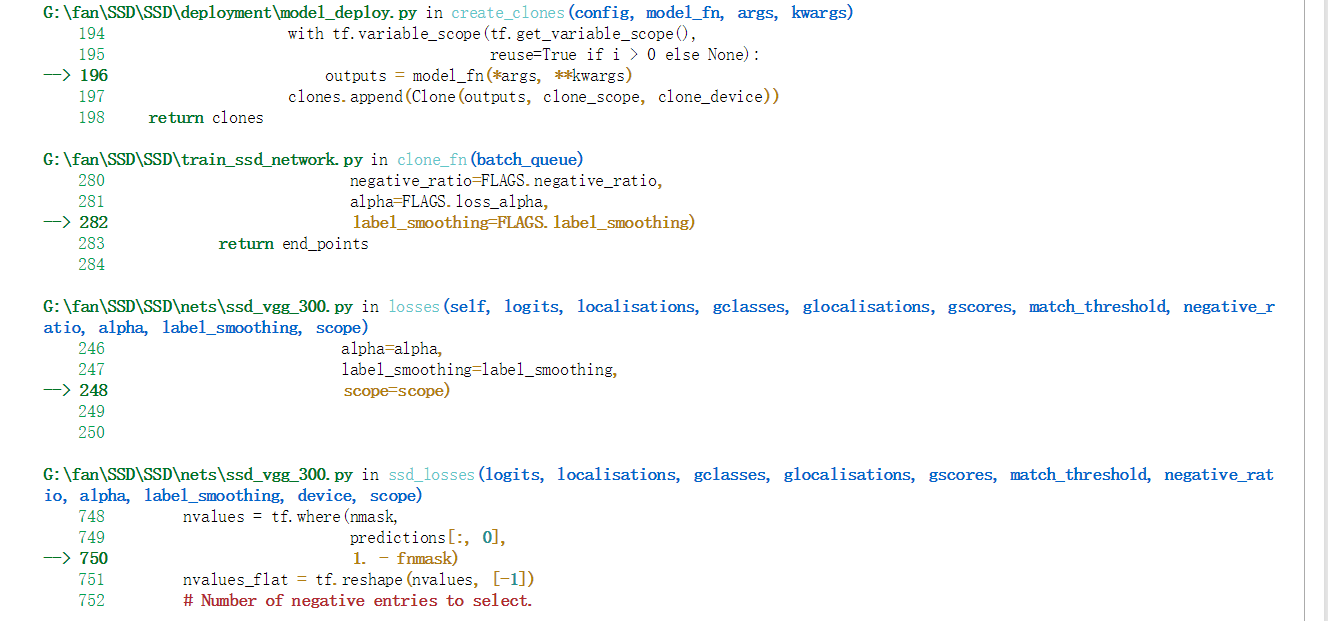
前面的网络模型部分已经修改完成且不报错。
但是在进行训练操作的时候会出现
’ValueError: Dimension 0 in both shapes must be equal, but are 233920 and 251392. Shapes are [233920] and [251392]. for 'ssd_losses/Select' (op: 'Select') with input shapes: [251392], [233920], [251392].
‘
‘两个形状中的尺寸0必须相等,但分别为233920和251392。形状有[233920]和[251392]。对于输入形状为[251392]、[233920]、[251392]的''ssd_losses/Select' (op: 'Select')

SSD loss function.
===========================================================================
def ssd_losses(logits, localisations,
gclasses, glocalisations, gscores,
match_threshold=0.5,
negative_ratio=3.,
alpha=1.,
label_smoothing=0.,
device='/cpu:0',
scope=None):
with tf.name_scope(scope, 'ssd_losses'):
lshape = tfe.get_shape(logits[0], 5)
num_classes = lshape[-1]
batch_size = lshape[0]
# Flatten out all vectors!
flogits = []
fgclasses = []
fgscores = []
flocalisations = []
fglocalisations = []
for i in range(len(logits)):
flogits.append(tf.reshape(logits[i], [-1, num_classes]))
fgclasses.append(tf.reshape(gclasses[i], [-1]))
fgscores.append(tf.reshape(gscores[i], [-1]))
flocalisations.append(tf.reshape(localisations[i], [-1, 4]))
fglocalisations.append(tf.reshape(glocalisations[i], [-1, 4]))
# And concat the crap!
logits = tf.concat(flogits, axis=0)
gclasses = tf.concat(fgclasses, axis=0)
gscores = tf.concat(fgscores, axis=0)
localisations = tf.concat(flocalisations, axis=0)
glocalisations = tf.concat(fglocalisations, axis=0)
dtype = logits.dtype
# Compute positive matching mask...
pmask = gscores > match_threshold
fpmask = tf.cast(pmask, dtype)
n_positives = tf.reduce_sum(fpmask)
# Hard negative mining...
no_classes = tf.cast(pmask, tf.int32)
predictions = slim.softmax(logits)
nmask = tf.logical_and(tf.logical_not(pmask),
gscores > -0.5)
fnmask = tf.cast(nmask, dtype)
nvalues = tf.where(nmask,
predictions[:, 0],
1. - fnmask)
nvalues_flat = tf.reshape(nvalues, [-1])
# Number of negative entries to select.
max_neg_entries = tf.cast(tf.reduce_sum(fnmask), tf.int32)
n_neg = tf.cast(negative_ratio * n_positives, tf.int32) + batch_size
n_neg = tf.minimum(n_neg, max_neg_entries)
val, idxes = tf.nn.top_k(-nvalues_flat, k=n_neg)
max_hard_pred = -val[-1]
# Final negative mask.
nmask = tf.logical_and(nmask, nvalues < max_hard_pred)
fnmask = tf.cast(nmask, dtype)
# Add cross-entropy loss.
with tf.name_scope('cross_entropy_pos'):
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits,
labels=gclasses)
loss = tf.div(tf.reduce_sum(loss * fpmask), batch_size, name='value')
tf.losses.add_loss(loss)
with tf.name_scope('cross_entropy_neg'):
loss = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits,
labels=no_classes)
loss = tf.div(tf.reduce_sum(loss * fnmask), batch_size, name='value')
tf.losses.add_loss(loss)
# Add localization loss: smooth L1, L2, ...
with tf.name_scope('localization'):
# Weights Tensor: positive mask + random negative.
weights = tf.expand_dims(alpha * fpmask, axis=-1)
loss = custom_layers.abs_smooth(localisations - glocalisations)
loss = tf.div(tf.reduce_sum(loss * weights), batch_size, name='value')
tf.losses.add_loss(loss)
研究了一段时间的源码 (因为只是SSD-Tensorflow-Master中的ssd_vgg_300.py中定义网络结构的那部分做了修改 ,loss函数代码部分并没有进行改动)所以没所到错误所在,网上也找不到相关的解决方案。
希望大神能够帮忙解答
感激不尽~






