关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
lca1rus
2021-11-03 16:05
采纳率: 62.5%
浏览 87
首页
Python
已结题
xpath返回空值的问题,希望有人能解答
python
爬虫
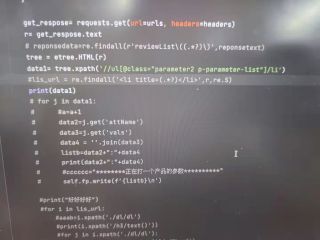
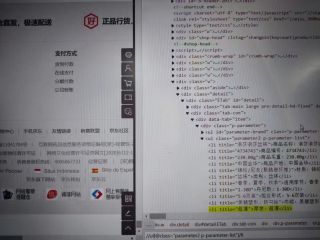
为什么在浏览器上都可以看出我的xpath路径是可以找到的
但是pycharm上确实输出的是空值,困扰了我好久,希望能人能解答
收起
写回答
好问题
0
提建议
关注问题
微信扫一扫
点击复制链接
分享
邀请回答
编辑
收藏
删除
收藏
举报
3
条回答
默认
最新
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
江天暮雪丨
2021-11-03 16:45
关注
url方便发一下?本地xpath试试
本回答被题主选为最佳回答
, 对您是否有帮助呢?
本回答被专家选为最佳回答
, 对您是否有帮助呢?
本回答被题主和专家选为最佳回答
, 对您是否有帮助呢?
解决
无用
评论
打赏
微信扫一扫
点击复制链接
分享
举报
评论
按下Enter换行,Ctrl+Enter发表内容
查看更多回答(2条)
向“C知道”追问
报告相同问题?
提交
关注问题
python
爬虫
xpath
出来
空值
_
python
爬虫--
xpath
方式清洗数据,class内容中有空格,清洗失败怎么办?...
2020-12-03 21:02
weixin_39841002的博客
python
爬虫--
xpath
方式清洗数据,清洗失败?(class内容中有空格)目标:爬取类似下图中帖子的图片步骤一、找到该帖子的源代码为什么现在培训班出来的Java学员都找不到工作?步骤二、爬取网页内容,使用
xpath
方法获取...
Python
爬取分析51Job数据并可视化岗位信息
2024-02-02 22:49
这有助于我们了解
Python
岗位的整体概况。 然后,我们进入可视化阶段。
Python
提供了许多优秀的可视化库,如`matplotlib`和`seaborn`,它们能帮助我们创建直观的图表。在这里,我们将使用它们来绘制薪资的柱状图,...
python
中
xpath
语法怎么用_
Python
爬虫之
Xpath
语法
2020-12-05 01:43
weixin_39677027的博客
XPath
是一种寻找信息的XML文档的语言。
XPath
是用于导航XML文档中的元素和属性。
XPath
包含超过100个内置函数。这些函数是用于字符串值,数值、日期和时间比较,节点和QName处理序列...在
XPath
中,有七种类型的节点:元素...
Python
爬虫实战:
XPath
语法详解与页面节点提取
2025-12-27 15:42
python 爬虫工程师的博客
本文系统讲解
XPath
语法在
Python
爬虫中的应用,重点介绍lxml库集成、核心语法(路径表达式、属性筛选、索引定位等)及实战技巧。通过豆瓣电影Top250和知乎热榜两大案例,展示
XPath
的高效数据提取能力,并与...
Python
爬虫从入门到进阶:
XPath
解析与实战案例(豆瓣 Top250+4399 登录抓取)
2025-09-17 17:49
Hs_QY_FX的博客
本文介绍了
Python
爬虫技术,从入门到进阶涵盖了
XPath
解析和两个实战案例(豆瓣Top250和4399登录抓取)。主要内容包括:1. 爬虫基础工具与
XPath
解析技术,重点讲解元素定位和属性提取;2. 豆瓣Top250爬取案例,实现...
Python
爬虫大师课:HTML解析与
XPath
魔法的王者级教程
2025-08-27 14:33
allenXer的博客
《
Python
爬虫高阶指南:
XPath
解析与智能对抗技术》摘要:本文深入探讨专业级爬虫开发的核心技术,重点解析
XPath
高级应用(轴定位、谓词表达式等)和动态网页解析策略。通过对比不同解析器性能,提出多重定位与智能...
Python
爬虫基础之Requests和
XPath
实例(三)
2018-12-21 20:08
Blessy_Zhu的博客
如何用
Python
爬取多个页面的数据信息呢?这次通过豆瓣网top250的图书信息来进行学习。首先给出页面(如图1所示)的URL: https://book.douban.com/top250 ,我们要爬去的信息是:书名、链接、评分、一句话评价…… ...
xpath
里面if判断一个值不为空_一步一步学
Python
3(小学生也适用) 第十五篇:条件判断...
2020-12-07 06:12
weixin_39675289的博客
一、条件判断在
Python
中,我们使用if else语句对条件进行判断,然后根据不同条件结果,执行该条件下相对应的代码。在
Python
中,if else语句可以细分为三种形式:1.1 if语句if 表达式:代码块'''判断小明是否满18岁,...
Python
爬虫开发学习全教程第二版,爆肝十万字【建议收藏】
2021-10-17 13:35
五包辣条!的博客
上次整理的爬虫教程反响不错,但是还是有小伙伴表示不够细致,今天带了升级版,全文很长,建议先收藏下来。 一、爬虫基础 爬虫概述 知识点: 了解 爬虫的概念 了解 爬虫的作用 了解 爬虫的分类 ...
Python
没爬取到数据,求看这个是什么原因?
2024-09-05 15:04
bug菌¹的博客
并非所有的
解答
都能解决每个人的
问题
,在此
希望
屏幕前的你能够给予宝贵的理解,而不是立刻指责或者抱怨!如果你有更优解,那建议你出教程写方案,一同学习!共同进步。ok,以上就是我这期的Bug修复内容啦,如果还想...
没有解决我的问题,
去提问
向专家提问
向AI提问
付费问答(悬赏)服务下线公告
◇ 用户帮助中心
◇ 新手如何提问
◇ 奖惩公告
问题事件
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
系统已结题
11月11日
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
已采纳回答
11月3日
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
创建了问题
11月3日

 分享
分享 系统已结题
11月11日
系统已结题
11月11日 已采纳回答
11月3日
创建了问题
11月3日
已采纳回答
11月3日
创建了问题
11月3日



