关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
Υδροχόος菜
2021-11-06 10:39
采纳率: 100%
浏览 40
首页
有问必答
已结题
python爬虫B站评论数,为什么有一个数据爬不下来
有问必答
python
爬虫
评论这一块的内容从格式上来看都是一样的呀,为什么“评论”两个字能爬下来,具体的评论数没有?
收起
写回答
好问题
0
提建议
关注问题
微信扫一扫
点击复制链接
分享
邀请回答
编辑
收藏
删除
收藏
举报
2
条回答
默认
最新
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
CSDN专家-黄老师
2021-11-06 11:05
关注
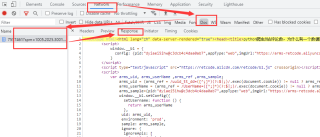
你用request的话,要看network的响应内容,不是element的。如图
本回答被题主选为最佳回答
, 对您是否有帮助呢?
本回答被专家选为最佳回答
, 对您是否有帮助呢?
本回答被题主和专家选为最佳回答
, 对您是否有帮助呢?
解决
无用
评论
打赏
微信扫一扫
点击复制链接
分享
举报
评论
按下Enter换行,Ctrl+Enter发表内容
查看更多回答(1条)
向“C知道”追问
报告相同问题?
提交
关注问题
基于
Python
3的
B站
综合
数据
爬虫
工具.zip
2025-05-25 13:38
本次介绍的“基于
Python
3的
B站
综合
数据
爬虫
工具”正是
一个
为满足此类需求而设计的实用工具。 该工具使用
Python
3作为开发环境,利用其丰富的第三方库,如requests用于网络请求,BeautifulSoup和lxml用于网页内容解析...
python
爬虫
代码源码.rar
2023-02-25 12:42
python
爬虫
程序可用于收集
数据
。这也是最直接和最常用的方法。由于
爬虫
程序是
一个
程序,程序运行得非常快,不会因为重复的事情而感到疲倦,因此使用
爬虫
程序获取大量
数据
变得非常简单和快速。 由于99%以上的网站是...
新浪微博
爬虫
,用
python
爬
取新浪微博
数据
,并下载微博图片和微博视频
2024-05-02 11:18
新浪微博
爬虫
,用
python
爬
取新浪微博
数据
,并下载微博图片和微博视频 连续
爬
取
一个
或多个微博用户的
数据
,并将结果信息写入文件。写入信息几乎包括了用户微博的所有
数据
,主要有用户信息和微博信息两大类,前者包含...
【2023最新
B站
评论
爬虫
】用
python
爬
取上千条哔哩哔哩
评论
2023-09-12 22:45
马哥python说的博客
马哥原创:用
python
爬
取哔哩哔哩的
B站
评论
数据
,单个视频可
爬
上万条。
分享
Python
7个
爬虫
小案例(附源码)
2022-10-22 07:00
艾派森的博客
本次的7个
python
爬虫
小案例涉及到了re正则、xpath、beautiful soup、selenium等知识点,非常适合刚入门
python
爬虫
的小伙伴参考学习。
Python
爬虫
以及
数据
可视化分析
2020-12-25 17:43
反卷三明治的博客
Python
爬虫
以及
数据
可视化分析之
B站
动漫排行榜信息
爬
取分析 简书地址:https://www.jianshu.com/u/40ac87350697 简单几步,通过
Python
对
B站
番剧排行
数据
进行
爬
取,并进行可视化分析 源码文件可以参考Github上传的...
爬
取微博
数据
_
爬
取微博_
python
爬虫
_
爬
取微博
数据
并可视化_
数据
开发_微博分析_
2021-10-02 16:25
在本文中,我们将深入探讨如何使用
Python
爬虫
技术来
爬
取微博
数据
,分析情感倾向,以及将结果以可视化的方式展示。首先,让我们了解为何要进行微博
数据
爬
取以及它的价值。 微博作为中国的
一个
社交媒体平台,拥有海量...
Python
爬虫
豆瓣电影TOP150的信息并对
爬
取
评论
数
第一的电影并将
评论
进行词云展示
2020-04-27 23:36
Python
爬虫
豆瓣电影TOP150的信息并对
爬
取
评论
数
第一的电影并将
评论
进行词云展示,信息包含电影详情链接,图片链接,影片中文名,影片外国名,评分,评价
数
,概况,导演,主演,年份,地区,类别等内容,将其在Excel中展示
Python
爬虫
—
爬
取微博
评论
数据
2025-05-07 17:38
小尤笔记的博客
下面我将详细讲解如何使用
Python
爬
取微博
评论
数据
,包括完整的代码实现和分步骤解释。
python
爬虫
情感分析/舆情分析,
一个
可以直接拿来用的小作品
2023-01-12 22:29
在IT领域,特别是
数据
分析和人工智能应用中,"
Python
爬虫
"和"情感分析/舆情分析"是两个重要的技术分支。这个小作品集成了这两个技术,为视频创作者提供了
一个
观众评议分析系统,帮助他们理解观众的情感倾向,从而...
没有解决我的问题,
去提问
向专家提问
向AI提问
付费问答(悬赏)服务下线公告
◇ 用户帮助中心
◇ 新手如何提问
◇ 奖惩公告
问题事件
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
系统已结题
11月14日
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
已采纳回答
11月6日
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
创建了问题
11月6日



 分享
分享
 分享
分享 系统已结题
11月14日
系统已结题
11月14日 已采纳回答
11月6日
创建了问题
11月6日
已采纳回答
11月6日
创建了问题
11月6日


