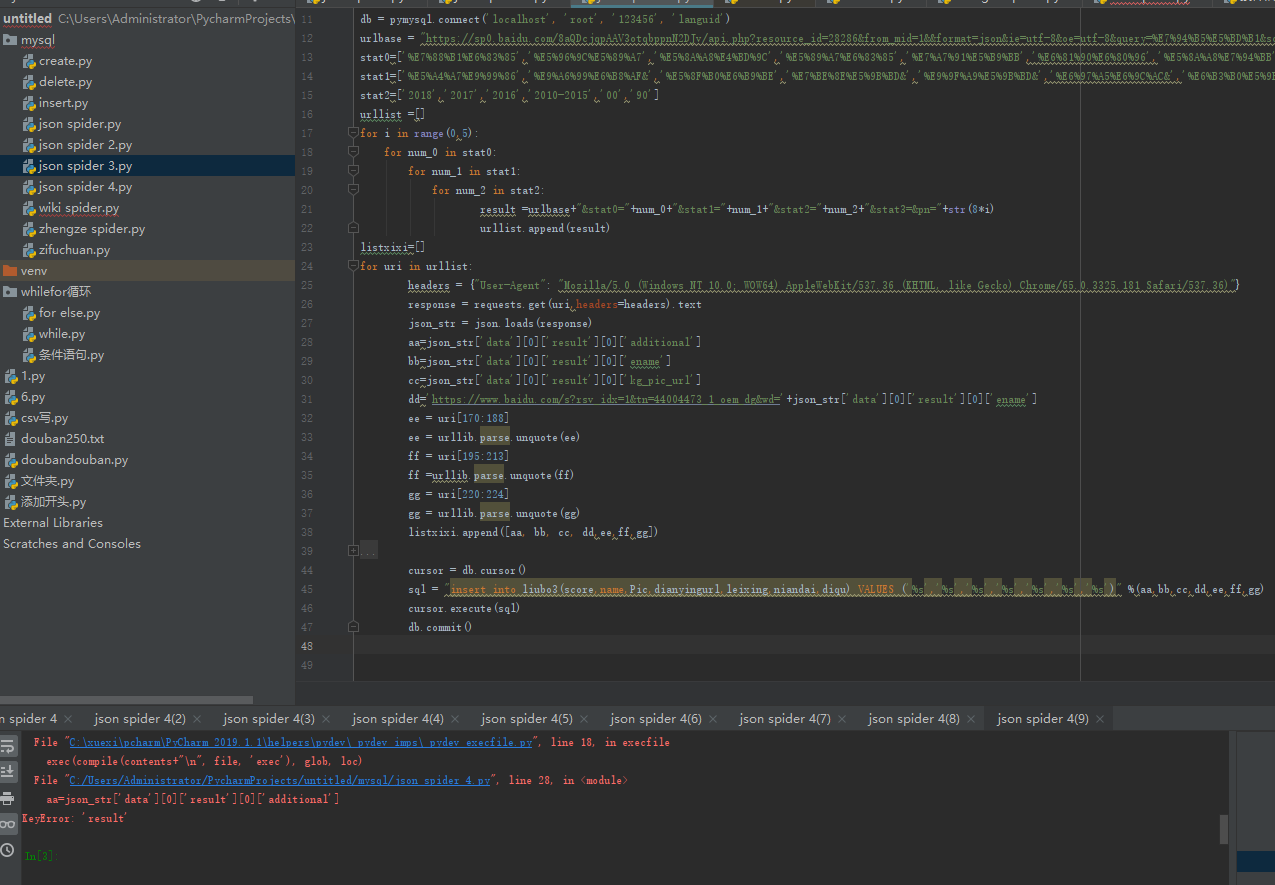
因为每一类的电影页数不确定
所以for循环循环到的页面所爬取的有的json数据是
{"data":[{"data":"no result"}],"status":0}这样的(就是该页数是空的 没有能够爬到的)
会提示keyerror 应该怎么解决呢 用default提示是str不是字典 有什么办法可以直接跳过吗

因为每一类的电影页数不确定
所以for循环循环到的页面所爬取的有的json数据是
{"data":[{"data":"no result"}],"status":0}这样的(就是该页数是空的 没有能够爬到的)
会提示keyerror 应该怎么解决呢 用default提示是str不是字典 有什么办法可以直接跳过吗
 分享
分享
加个语句判断一下是不是字典
if isinstance(json_str, dict)
do your action
或者取key时候:
dict_movie.get('your key')
没有key会返回None
分享


