关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
m0_58844937
2021-11-20 15:43
采纳率: 94.3%
浏览 230
首页
Python
已结题
Python爬虫 XPath 爬取的数据为空
python
这是题目
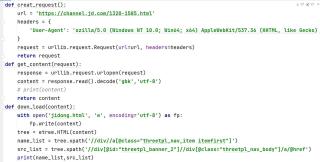
这是代码
输出
写入的HTML文件 要爬取的内容没有在div里面
,div是空的
收起
写回答
好问题
0
提建议
关注问题
微信扫一扫
点击复制链接
分享
邀请回答
编辑
收藏
删除
收藏
举报
2
条回答
默认
最新
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
达娃里氏
2021-11-21 16:57
关注
本回答被题主选为最佳回答
, 对您是否有帮助呢?
本回答被专家选为最佳回答
, 对您是否有帮助呢?
本回答被题主和专家选为最佳回答
, 对您是否有帮助呢?
解决
2
无用
1
评论
打赏
微信扫一扫
点击复制链接
分享
举报
评论
按下Enter换行,Ctrl+Enter发表内容
查看更多回答(1条)
向“C知道”追问
报告相同问题?
提交
关注问题
Python
使用
xpath
爬取
网站
数据
2025-04-03 17:28
Python
结合
XPath
进行网站
数据
爬取
是一种非常高效的技术方案。它不仅可以帮助我们快速地从复杂的HTML结构中提取所需
数据
,还可以通过灵活的
XPath
表达式适应各种不同的
数据
爬取
需求。然而,为了确保
爬虫
程序的稳定运行...
Python
用
xpath
爬取
数据
返回空列表解决
2021-12-21 21:40
jackwen888的博客
Python
用
xpath
爬取
数据
返回空列表解决
python
爬虫
爬取
电影
数据
并做可视化
2023-09-18 13:26
程序小武的博客
对
爬取
的
数据
进行可视化
Python
网页
爬虫
爬取
豆瓣Top250电影
数据
——
Xpath
数据
解析
2023-09-26 12:04
jojo来根易安的博客
本次程序只
爬取
了豆瓣top250电影的展示页面的
数据
,没有
爬取
电影详情页的
数据
。在前面我们已经获取了每一部电影详情页的链接links,如果想要
爬取
电影的详情页,可以通过for循环遍历列表links,对每一个详情页发起...
Python
用
xpath
爬取
数据
返回空列表解决
python
爬虫
,关于使用
xpath
写
爬虫
获取不到内容, 获取到空列表的解决方案
2021-11-26 15:11
'一生所爱的博客
之前在做的
爬虫
都是用的
xpath
去获取内容,又想偷懒,所以就直接在源码那里直接复制路径, 然后就很容易踩雷了(我算是踩了很多坑了,不知道有没有小伙伴和我一样踩过这样的坑): 此时可能会得到如下路径: /...
python
爬虫
之
xpath
爬取
之全国城市
爬取
2024-06-05 21:37
杂记铺的博客
python
爬虫
之
xpath
爬取
之全国城市
爬取
python
爬取
数据
返回空列表_
Python
用
xpath
爬取
数据
返回空列表解决
2020-11-29 14:04
weixin_39918043的博客
笔者以
爬取
2018年AAAI人工智能顶会论文元
数据
为例。其中包括标题(title)和摘要(abstract)等字段前言:首先需要查看该网页是否可以
爬取
,通过在URL后加入/robots,txt可以查看。①tbody问题笔者通过谷歌浏览器选取上图...
Python
-
爬虫
(
xpath
数据
解析,
爬取
信息实战)
2022-09-01 12:37
BaiRong-NUC的博客
Python
-
爬虫
(
xpath
数据
解析,
爬取
链接网信息练习)
Python
爬虫
爬取
豆瓣
数据
XPath
的使用
2022-01-18 17:13
侯小啾的博客
通过使用requests. lxml, csv 三个模块,
爬取
豆瓣电影Top250的电影名称,评分,引言,详情页的url。
爬取
1-10页,并保存在csv文件中。
python
使用
xpath
爬取
网页
数据
2022-07-20 17:45
不聪明的小侦探的博客
使用
python
中resquests模块来
爬取
网页
数据
没有解决我的问题,
去提问
向专家提问
向AI提问
付费问答(悬赏)服务下线公告
◇ 用户帮助中心
◇ 新手如何提问
◇ 奖惩公告
问题事件
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
系统已结题
11月29日
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
已采纳回答
11月21日
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
修改了问题
11月21日
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
创建了问题
11月20日




 分享
分享 系统已结题
11月29日
系统已结题
11月29日 已采纳回答
11月21日
修改了问题
11月21日
创建了问题
11月20日
已采纳回答
11月21日
修改了问题
11月21日
创建了问题
11月20日