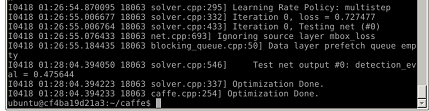
大佬们好,我是深度学习小白一枚,想请教一个问题,我在做有关ssd算法的全景图像车辆检测,但是目前训练迭代6万次的模型准确率很低(47%),请问需要做怎么样的改进可以提高它的准确率呢,多谢指教了!
收起
当前问题酬金
¥ 0 (可追加 ¥500)
支付方式
扫码支付
支付金额 15 元
提供问题酬金的用户不参与问题酬金结算和分配
支付即为同意 《付费问题酬金结算规则》
应该是训练不充分,用好一点的机器慢慢算,不着急
报告相同问题?

 分享
分享




