解析html的一个问题

我需要爬取这里的文字
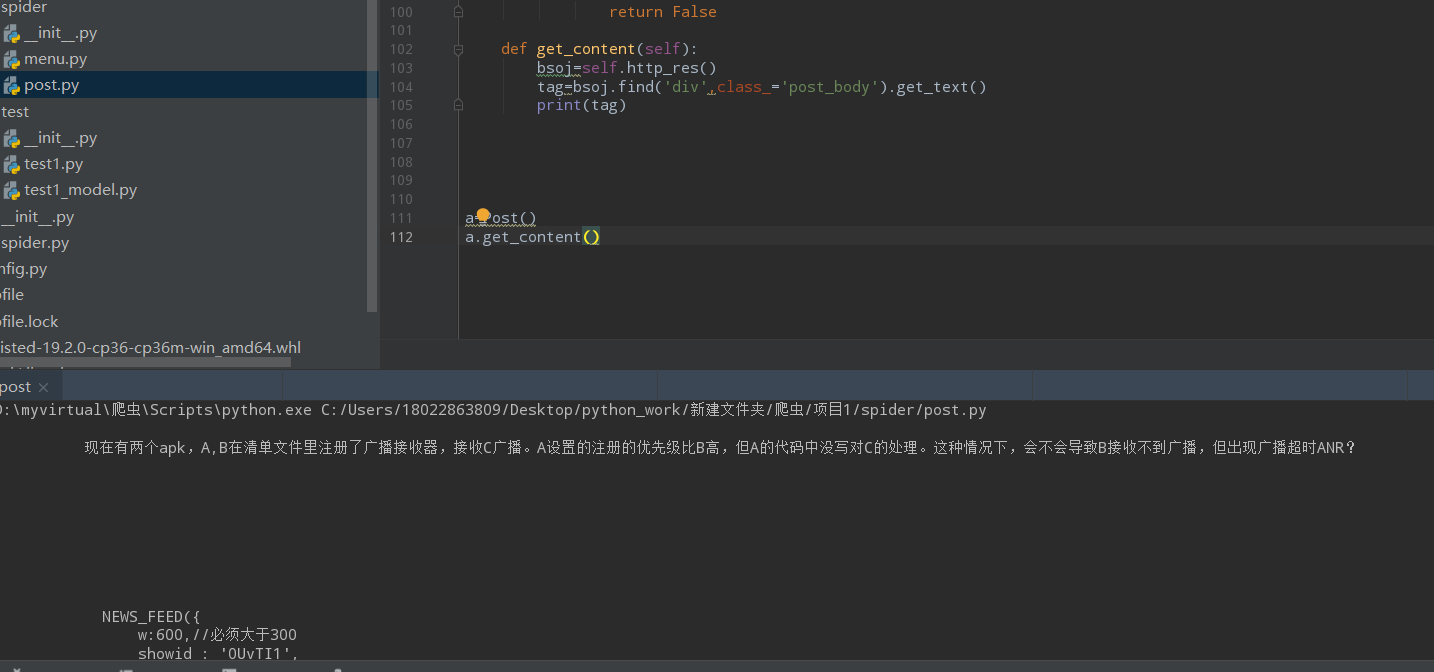
但是爬取出来后多了一段东西,这个是什么,应该怎么处理掉它

python爬虫解析html的一个问题

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


2条回答 默认 最新
 threenewbee 2019-04-19 09:50关注
threenewbee 2019-04-19 09:50关注看上去这些内容是网页本来就有的,爬虫代码没有问题。
你可以用正则表达式自己再过滤下。这段内容前面似乎有很多连续的换行,可以作为特征。本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
- 2019-04-18 22:45回答 2 已采纳 看上去这些内容是网页本来就有的,爬虫代码没有问题。 你可以用正则表达式自己再过滤下。这段内容前面似乎有很多连续的换行,可以作为特征。
- 2022-06-24 19:43回答 1 已采纳 其实有的,但是这个网站应该是为了懒加载把url用base64密了一下,然后再动态加载, 其实我下面发的这个就是url 是base64后的url 解码后就是https://s1.aigei.com/
- 2021-11-19 14:39回答 1 已采纳 第一个问题,你用html.xpath('//div[@class="co_content8"]/ul/table')找不到,是因为在table那一类,有很多分支标签,所以定位不到具体的元素。第二个问题
- 2020-09-19 12:00主要介绍了Python HTML解析器BeautifulSoup用法,结合实例形式详细分析了第三方库BeautifulSoup实现的爬虫解析器功能具体操作技巧,需要的朋友可以参考下
- 2023-02-17 09:21回答 5 已采纳 你的原代码拷贝过来执行的话,name返回的是None,也就是说你的选择器没有找到你期望的内容,调试代码修改如下: 注意看打印输出的内容: 所以检查下css选择器的代码是否正确吧 有帮助的话,请点采
- 2022-03-18 12:30回答 2 已采纳 driver.swith_to.window(driver.window_handles[1]),函数名写错了,不是swith是switch,少写了个c,改成:driver.switch_to.win
- 2022-02-26 20:51回答 2 已采纳 这个接口返回的是jsonp数据,不是json,要获取text替换掉回调函数名称和前后的括号后才是json数据
- 2020-09-18 04:59主要介绍了Python爬虫解析网页的4种方式实例及原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
- 2022-04-23 22:42回答 1 已采纳 这样写 div = ..... if not div: div = ...
- 2023-03-08 13:26回答 3 已采纳 他还引用了另一个包,你一起弄进来
- 2021-12-30 23:54回答 2 已采纳 ulrs = re.findall('<img src="(.*?)" alt=".*?">', html) 改成这样就行了,有帮助的话采纳一下哦!谢谢!
- 2023-03-24 20:54Python爬虫详细解析.doc Python爬虫详细解析.doc Python爬虫详细解析.doc Python爬虫详细解析.doc Python爬虫详细解析.doc Python爬虫详细解析.doc Python爬虫详细解析.doc Python爬虫详细解析.doc
- 2022-01-04 18:04回答 2 已采纳 我是JAVA的xpath html.xpath("//table[@id='main_table_countries_today']/tbody/tr[@style=' ']").你看着修改下
- 2020-09-16 22:38主要介绍了Python爬虫工具requests-html使用解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下
- 2021-06-06 14:16Python爬虫解析XPATH讲义
- 没有解决我的问题, 去提问


悬赏问题
- ¥15 安卓adb backup备份应用数据失败
- ¥15 eclipse运行项目时遇到的问题
- ¥15 关于#c##的问题:最近需要用CAT工具Trados进行一些开发
- ¥15 南大pa1 小游戏没有界面,并且报了如下错误,尝试过换显卡驱动,但是好像不行
- ¥15 没有证书,nginx怎么反向代理到只能接受https的公网网站
- ¥50 成都蓉城足球俱乐部小程序抢票
- ¥15 yolov7训练自己的数据集
- ¥15 esp8266与51单片机连接问题(标签-单片机|关键词-串口)(相关搜索:51单片机|单片机|测试代码)
- ¥15 电力市场出清matlab yalmip kkt 双层优化问题
- ¥30 ros小车路径规划实现不了,如何解决?(操作系统-ubuntu)