

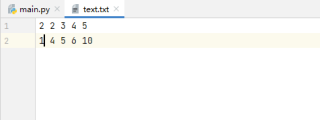
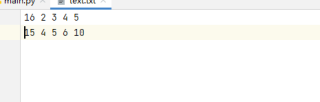
把2改为16,把1改为15。也就是第一列的内容进行修改替换,其他不变。

 分享
分享
b = []
with open('text.txt', 'r',encoding='utf8') as f:
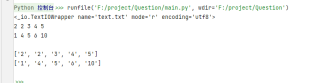
print(f)
while True:
_ = f.readline()
print(_)
if _:
b.append(_.split(' '))
else:
break
for i in range(len(b)):
print(b[i])
if b[i][0] == '2':
b[i][0] = '16'
elif b[i][0] == '1':
b[i][0] = '15'
with open('text.txt', 'w+', encoding='utf8') as f:
for i in b:
f.writelines(' '.join(i))
分享  系统已结题
12月4日
系统已结题
12月4日 已采纳回答
11月26日
创建了问题
11月26日
已采纳回答
11月26日
创建了问题
11月26日

