
打算在中关村网站按照手机型号查询手机具体参数和用户评论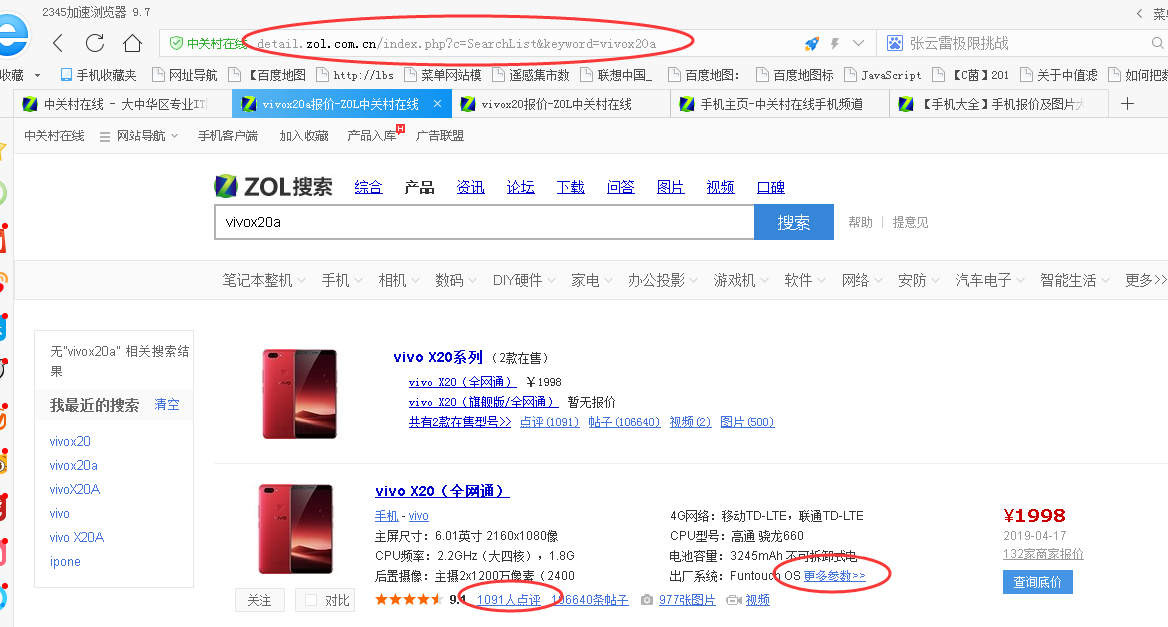
网址为http://detail.zol.com.cn/index.php?c=SearchList&keyword=vivox20a
一开始按照 base = http://detail.zol.com.cn/index.php?
然后在后面加参数的方法爬取,发现返回是空的,f12中查看了一下,感觉也不是ajax加载的,并没有看到json格式的数据。。
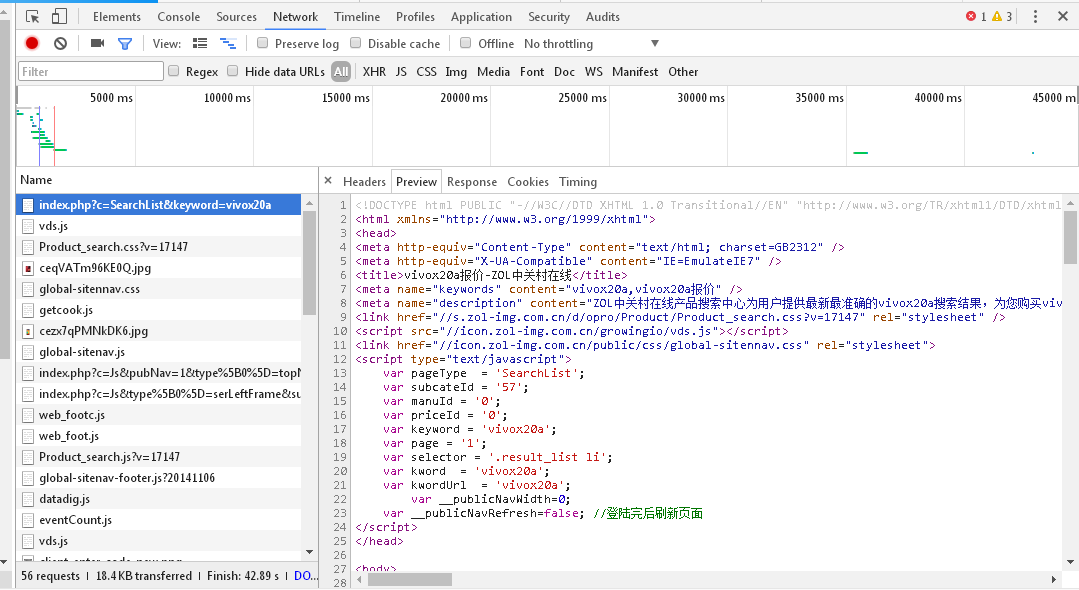
所以还是不知道问题出在哪里了,下面是我的代码,返回一直为空,拜托拜托大佬们给我一点思路或者用什么方法去爬,我是真实刚入门小白……
import requests
from urllib.parse import urlencode
import json
base_url = "http://detail.zol.com.cn/index.php?"
headers = {
"Host": "detail.zol.com.cn",
"Referer": "http://detail.zol.com.cn/index.php?c=SearchList&keyword=vivox20a",
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.90 Safari/537.36 2345Explorer/9.7.0.18838",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Encoding": "gzip,deflate",
"Accept-Language": "zh-CN,zh;q=0.8"
}
def get_page(key):
parmas = {
"c":"SearchList",
"subcateId":57,
"keyword": key
}
url = base_url+urlencode(parmas)
print(url)
try:
r = requests.get(url, headers = headers)
if r.content:
return json.loads(r.text)
except requests.ConnectionError as e:
print(e.args)
if __name__ == '__main__':
get_page("vivox20a")





