如图所示,在request进入downloader之前,headers里是没有cookie字段的,但是在下载结束后,request的headers字段里出现了cookie字段,且该cookie内容为上一次请求返回的set-cookie的内容,但是这里我其实是不需要这个request携带任何cookie进行请求的,尝试过在settting里设置cookies-enabled=False,这样虽然request.headers里的确没有cookie可以得到我希望的请求头,但是后续需要携带cookie的请求就没办法继续正常请求了,请问如何设置本次请求不携带上一次请求的xin'xi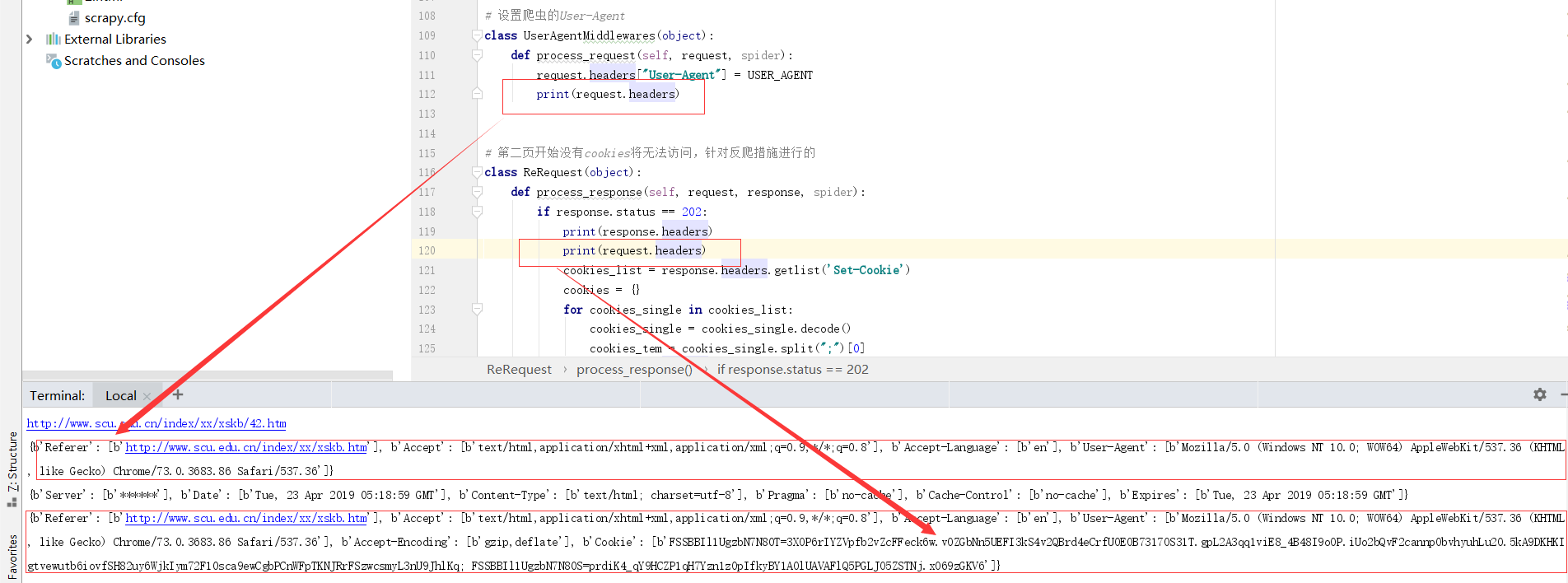

求解关于scrapy请求会自动携带上一次请求中的set-cookie字段的问题

- 写回答
- 好问题 0 提建议
- 关注问题
 分享
分享- 邀请回答
-

2条回答 默认 最新
- Yajun-Z 2019-04-24 18:09关注
在你不需要的地方手动清除不可行吗?或者你每次在不需要
cookies的地方深拷贝一份setting里面的headers解决 无用评论 打赏举报 分享
- 2026-02-23 19:01Python爬虫项目的博客 监控与日志 loguru==0.7.2 prometheus-client==0.20.0 # 配置管理 pydantic==2.7.1 python-dotenv==1.0.1 安装命令: bash pip install -r requirements.txt playwright install chromium # 安装Playwright浏览器...
- 2022-07-11 07:35「已注销」的博客 1. 先看一个最简单的爬虫。 import requests url = "http://www.cricode.com" r = requests.get(url) print(r.text) 2. 一个正常的爬虫程序 上面那个最简单的爬虫,是一个不完整的残疾的爬虫。因为爬虫程序通常...
- 2018-12-23 17:59weixin_30305735的博客 │ python就业班-淘宝-目录.txt│ ├─01 网络编程│ ├─01-基本概念│ │ 01-网络通信概述.flv│ │ 02-IP地址.flv│ │ 03-Linux、windows查看网卡信息.flv│ │ 04-ip地址的分类-ipv4和ipv6...
- 2018-09-01 11:25残烛0一0照月的博客 第一章 Python综合 1.对不定长参数的理解? 不定长参数有两种:*args和**kwargs; *args:是不定长参数,用来将参数打包成tuple给函数体调用; **kwargs:是关键字参数,打包关键字参数成dict给函数体调用; ...
- 2025-12-10 15:51flyair_China的博客 Y) = H(X)-H(X|Y) 相关性分析 相关性攻击 完美保密 H(M|C) = H(M) 一次一密 理想密码分析 复杂度理论 时间复杂度 O(n)、O(2^n) 算法安全性分析 暴力攻击复杂度 空间复杂度 内存使用量 内存受限攻击 内存攻击 P、NP、...
- 2019-09-26 11:57diandinai8712的博客 1、现有两元祖 (('a'),('b'),('c'),('d') ) ,请使用Python中的匿名函数生成列表 [ {'a':'c'},{'c':'d'}] 答案:v = list(map(lambda x,y:{x:y},data[0:2],data[2:4])) data = (('a'),('b'),('c'),('d') ) v = ...
- 2018-11-08 15:31DominicJi的博客 python面试题 第一章:python基础 数据类型: 1 字典: 1.1 现有字典 dict={‘a’:24,‘g’:52,‘i’:12,‘k’:33}请按字典中的 value 值进行排序? 1. sorted(dict.items(),key = lambda x:x[1]) 1.2 说...
- 2018-09-19 21:57weixin_30652879的博客 │ │ 05-(重点)运行python程序以及python交互模式,encode编码,发送udp的练习.flv │ │ 06-(重点)接收udp数据.flv │ │ 07-(重点)端口绑定的问题.flv │ │ 08-网络中重要概念复习.flv │...
- 2023-08-21 18:59「已注销」的博客 实际工作中,经常遇到一些需要很长时间才能完成的任务,例如压缩一个40G的目录,或者复制很大的文件。linux dns配置文件是“/etc/resolv.conf”,该配置文件用于配置DNS客户,它包含了主机的域名搜索顺序和DNS/...
- 2020-09-01 02:33island33的博客 自备留用 《Java语言程序设计》20春期末考核 1. 接口体中不应包含( )。...C 在Java中一个类不能同时继承一个类和实现一个接口 D 在Java中接口只允许单一继承 4. 编译并且执行以下代码,会出现什么情况...
- 没有解决我的问题, 去提问
