关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
xiaochuan1984
2021-12-03 22:07
采纳率: 50%
浏览 83
首页
有问必答
已结题
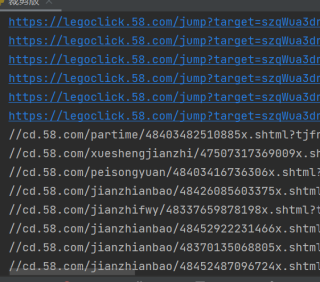
请问在python爬虫中抓取超链接时,有一部分超链接不完整,该怎么对那部分超链接添加拼接?
有问必答
python
爬虫
问题遇到的现象和发生背景
问题相关代码,请勿粘贴截图
运行结果及报错内容
我的解答思路和尝试过的方法
我想要达到的结果
收起
写回答
好问题
0
提建议
关注问题
微信扫一扫
点击复制链接
分享
邀请回答
编辑
收藏
删除
收藏
举报
2
条回答
默认
最新
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
CSDN专家-showbo
2021-12-03 22:13
关注
if
url
.startswith(
"https://"
)==
False
:
url
=
"https://"
+
url
本回答被题主选为最佳回答
, 对您是否有帮助呢?
本回答被专家选为最佳回答
, 对您是否有帮助呢?
本回答被题主和专家选为最佳回答
, 对您是否有帮助呢?
解决
1
无用
评论
打赏
微信扫一扫
点击复制链接
分享
举报
评论
按下Enter换行,Ctrl+Enter发表内容
查看更多回答(1条)
向“C知道”追问
报告相同问题?
提交
关注问题
Python
将图片以
超链接
形式插入Excel表格且以相对路径插入(发给任何人都能打开)
2024-05-15 15:06
小庄-Python办公的博客
Python
将图片以
超链接
形式插入Excel表格且以相对路径插入(发给任何人都能打开)
[
Python
从零到壹] 四.网络
爬虫
之入门基础及正则表达式
抓取
博客案例
2020-09-30 21:07
Eastmount的博客
欢迎大家来到“
Python
从零到壹”,在这里我将分享约200篇
Python
系列文章,带大家一起去学习和玩耍...第四篇文章将开启网络
爬虫
之旅,首先介绍基础知识及正则表达式的
爬虫
,希望对您有所帮助,文章
中
不足之处也请海涵。
用
Python
爬虫
抓取
网页上的所有图片链接:实战教程与代码示例
2025-01-20 10:56
Python爬虫项目的博客
抓取
网页上的图片链接是
爬虫
技术
中
的一种常见应用。发送HTTP请求:使用requests库向目标网页发送请求,获取网页的HTML源码。解析HTML源码:使用或lxml对HTML源码进行解析,提取出所有的标签。提取图片链接:从每个...
python
小项目——【
爬虫
爬取 网页
中
的内容及链接】
2024-11-18 18:33
Heris99的博客
python
爬虫
爬取网页内容小项目
人民网新闻
抓取
Python
(内附
完整
代码)
2024-09-04 23:52
木子津九的博客
本文在遵守Robots友好
爬虫
协议的前提下,在原始新闻列表页面向Web服务器发送携带cookies的请求,提取出子页面
超链接
,并存储成URL列表。遍历列表,通过selenium模拟浏览器技术,获得每一个子页面的网页内容,而后...
全网最全
python
爬虫
精进(体系学习)学完可就业(附源代码)
2021-05-17 19:00
yk 坤帝的博客
HTML(Hyper Text Markup Language)是用来描述网页的一种语言,也叫超文本标记语言 。 1-1、查看网页的 HTML 代码 ①、显示网页源代码 在网页任意地方点击鼠标右键,然后点击“显示网页源代码”。(Windows系统的...
Python
爬虫
系列-爬取小说(解决遇到cookie验证爬取不了的问题)
2024-05-14 15:59
虫鸣@蝶舞的博客
前段
时
间五一放假,在家没事干,在哔哩哔哩上瞎看,发现一个搞笑视频合集不错,闲来无事正好晚上催眠用,名称叫《我靠打爆学霸兑换黑科技》,里面的男主角生为一个高
中
生学习天赋惊人,各种逆袭外挂的人生,看的...
Python
3网络
爬虫
开发实战(15)Scrapy 框架的使用(第一版)
2024-09-17 13:25
Bigcrab__的博客
Scrapy 是一个基于
Python
开发的
爬虫
框架,是当前
Python
爬虫
生态
中
最流行的
爬虫
框架,该框架提供了非常多
爬虫
相关的基础组件,架构清晰,可拓展性极强。 之前大多是基于 requests 或 aiohttp 来实现
爬虫
的整个...
全网最全
python
爬虫
精进
2021-04-25 17:33
yk 坤帝的博客
爬虫
,从本质上来说,就是利用程序在网上拿到对我们有价值的数据。 2、明晰路径 2-1、浏览器工作原理 (1)解析数据:当服务器把数据响应给浏览器之后,浏览器并不会直接把数据丢给我们。因为这些数据是用计算机的...
【
Python
爬虫
实战】从多类型网页数据到结构化JSON数据的高效提取策略
2024-10-10 08:39
易辰君的博客
在互联网
爬虫
的过程
中
,面对大量网页数据,理解和区分不同类型的数据至关重要。无论是网页上的文本、数值信息,还是图片、链接、表格等内容,每一种数据类型都有其独特的结构和解析方法。通过合理利用相应的提取策略...
没有解决我的问题,
去提问
向专家提问
向AI提问
付费问答(悬赏)服务下线公告
◇ 用户帮助中心
◇ 新手如何提问
◇ 奖惩公告
问题事件
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
系统已结题
12月11日
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
已采纳回答
12月3日
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
创建了问题
12月3日


 分享
分享 分享
分享 系统已结题
12月11日
系统已结题
12月11日 已采纳回答
12月3日
创建了问题
12月3日
已采纳回答
12月3日
创建了问题
12月3日

