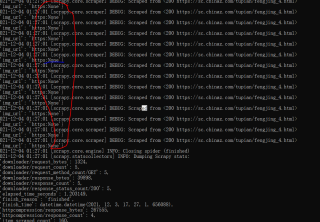
求大家帮忙看看
class DownloadimgSpider(scrapy.Spider):
name = 'downloadimg'
allowed_domains = ['sc.chinaz.com']
start_urls = ['https://sc.chinaz.com/tupian/fengjing.html']
urls = ['https://sc.chinaz.com/tupian/fengjing_%d.html'%i for i in range(2,5)]
urls_index = 0
def parse(self, response):
for div in response.xpath('//*[@id="container"]/div'):
img_url = div.xpath('./div/a/img/src').extract_first()
img_url = 'https:' + str(img_url)
item = DownloadimgItem()
item['img_url']=img_url
yield item
if self.urls_index < len(self.urls):
yield scrapy.Request(self.urls[self.urls_index], callback=self.parse)
self.urls_index += 1