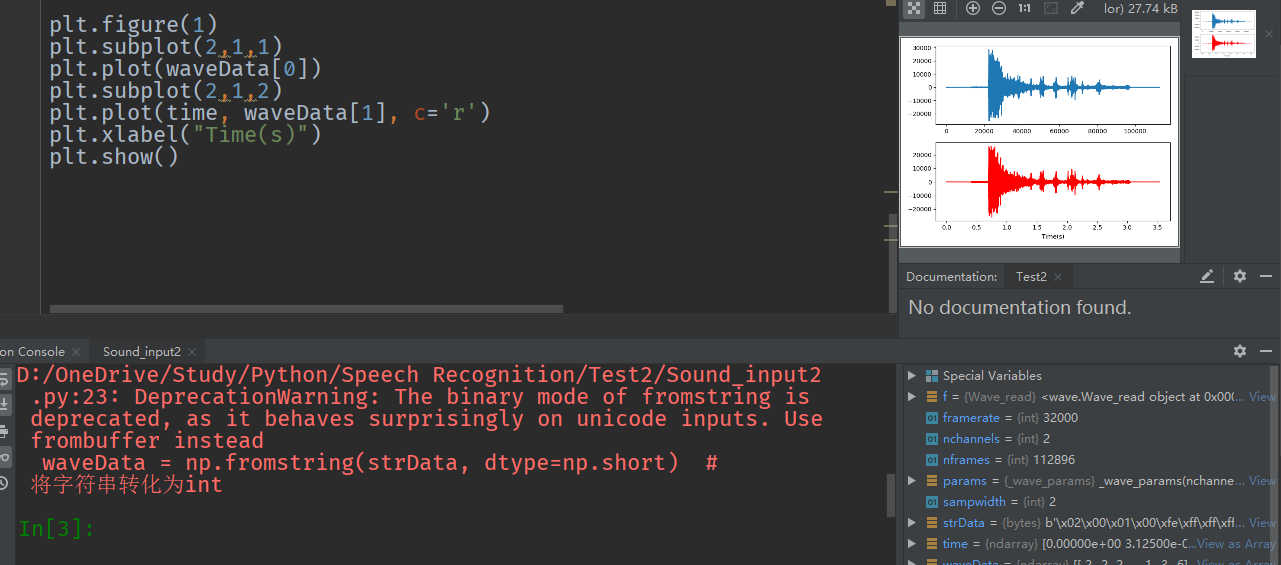
- 关于Python中声音信号的导入及显示;
- 相关代码:
import wave # 导入音频处理包
import matplotlib.pyplot as plt
import numpy as np
f = wave.open(r'D:\1.wav', 'rb')
params = f.getparams()
nchannels, sampwidth, framerate, nframes = params[:4]
# nchannels:声道数;sampwidth:量化位数(byte);framerate:采样频率;nframes:采样点数
print('channel:', nchannels, 'sampwidth:', sampwidth, 'framerate:', framerate, 'numframes:', nframes)
strData = f.readframes(nframes) # 读取音频,字符串格式
f.close()
# waveData = np.frombuffer(strData, dtype='S1', offset=0)
waveData = np.fromstring(strData, dtype=np.short) # 将字符串转化为int
waveData.shape = -1,2 # 将waveData数组改为2列,行数自动匹配。
waveData = waveData.T
time = np.arange(0, nframes) * (1.0 / framerate)
plt.figure(1)
plt.subplot(2,1,1)
plt.plot(time, waveData[0])
plt.subplot(2,1,2)
plt.plot(time, waveData[1], c='r')
plt.xlabel("Time(s)")
plt.show()
报错信息:
DeprecationWarning: The binary mode of fromstring is deprecated, as it behaves surprisingly on unicode inputs. Use frombuffer instead
waveData = np.fromstring(strData, dtype=np.short) # 将字符串转化为int系统建议改用frombuffer,因为fromstring提示将会被弃用,但是使用frombuffer后得出的数组经过转换后不能和time的维度相匹配,而fromstring后的数据是左右声道的数据。想要知道如何使用frombuffer来代替fromstring!
图像可以正常显示,不会报错但是会报警告,多谢大神的帮忙