

比如,有一个df,是ABCD四个班共10个小孩的年龄:
import pandas as pd
import numpy as np
data_dict = { "class":['A','B','A','C','D','B','C','A','D','C'] , 'age':[ 8, 11, 9, 12, 16, 6, 7, 10, 13, 5]}
data_df = pd.DataFrame(data_dict)
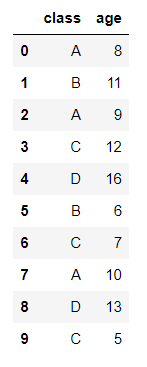
现在,需要将data_df按班级分组,求得每个班级的最大的年龄与每个班级的平均年龄的比值"ratio_age",并且data_df新增一列,以添加“ratio_age”。请问怎么做,才能够达到运算时速度最快(尽可能最快)?






