

问题遇到的现象和发生背景
问题相关代码,请勿粘贴截图
运行结果及报错内容
我的解答思路和尝试过的方法
我想要达到的结果
用python写爬虫,目标是获取排行总页面的作品名和排名,再获取该作品详情页部分信息。在生成详情页请求的代码处提示出错:
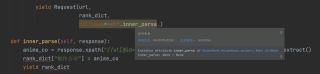
运行时的报错:

恳请指教 谢谢!急
from scrapy import Request
from scrapy.spiders import Spider
class AniRank(Spider):
name = 'AniRank'
this_page = 1
def __init__(self, name=None, ):
super().__init__(name)
self.inner_parse = None
def start_requests(self):
url = 'https://bangumi.tv/anime/browser?sort=rank'
yield Request(url) # 生成请求对象
def parse(self, response, **kwargs, ):
list_selector = response.xpath("//li/div[@class='inner']")
for one_selector in list_selector:
anime_rank = one_selector.xpath("span/text()").extract()[0]
anime_name = one_selector.xpath("h3/a/text()").extract()[0]
anime_year = one_selector.xpath("p/text()").extract()[0]
anime_year = anime_year.split('/')
for n in anime_year:
n = n.strip()
if ((n.find("年") == 4) and (n.find("月") >= 0)) or (n.find("-") == 4):
anime_year = n
rank_dict = {"bangumi排名": anime_rank,
"名称": anime_name,
"放送日期": anime_year, }
url = 'https://bangumi.tv' + one_selector.xpath("h3/a/@href").extract()[0] #生成详情页url
yield Request(url,
rank_dict,
callback=self.inner_parse,) #此处提示错误
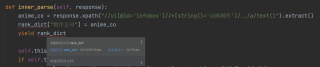
def inner_parse(self, response):
anime_co = response.xpath("//ul[@id='infobox']//*[string()='动画制作']/../a/text()").extract()
rank_dict["制作公司"] = anime_co
yield rank_dict
self.this_page += 1
if self.this_page <= 6:
next_url = "https://bangumi.tv/anime/browser?sort=rank&page=%d" % self.this_page
yield Request(next_url, self.parse)







