今天上课学校留的实践代码,搞不太懂,下面是具体要求和我写的代码,应该有错误,求大家指正教导。
编写程序生成3簇高斯数据,并用K-Means算法进行聚类。
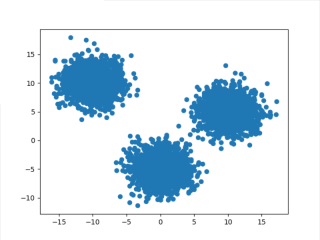
1.生成聚类中心为[(-10, 10), (0, -5), (10, 5)]的球状数据,共5000个数据点,每个类别方差为2,并要求每次运行结果一致。
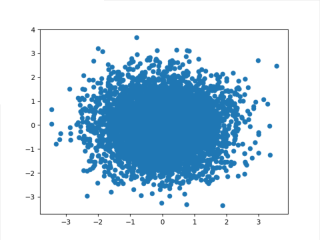
2.生成分类数据集(make_classification),共5000个数据点,10个特征,分类类别为3,某一类别由1个cluster组成,并要求每次运行结果一致。
3.绘制出上述两类数据。
4.用K-Means算法对上述两类数据进行聚类并显示聚类结果。
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs, make_classification
#X为样本特征,y为样本簇类别,共5000个样本,共3个簇,簇中心在[(-10, 10), (0, -5), (10, 5)],簇方差为2,random_state是随机种子,为使每次运行结果一致,我指定random_state=1
X,y = make_blobs(n_samples=5000, centers=[(-10, 10), (0, -5), (10, 5)], cluster_std=2,random_state=1)
plt.scatter(X[:,0], X[:,1], marker='o')
plt.show()
#用K-Means聚类方法来做聚类,选择k=3
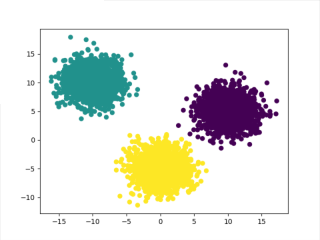
y_pred = KMeans(n_clusters=3, random_state=1).fit_predict(X)
#画图 c=target代表不同簇不同颜色,marker='o'是用来指定数据的显示形状
plt.scatter(X[:,0],X[:,1], c=y_pred, marker='o')
plt.show()
#X为样本特征,y为样本簇类别,共5000个数据点,10个特征,分类类别为3,某一类别由1个cluster组成
X,y = make_classification(n_samples=5000,n_features=10,n_classes=3,n_clusters_per_class=1,random_state=1)
plt.scatter(X[:,0], X[:,1], marker='o')
plt.show()
#用K-Means聚类方法来做聚类,选择k=3
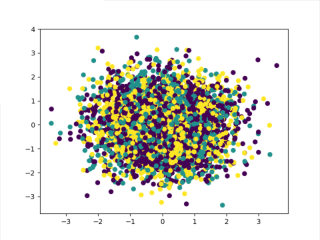
y_pred = KMeans(n_clusters=3, random_state=1).fit_predict(X)
#画图 c=target代表不同簇不同颜色,marker='o'是用来指定数据的显示形状
plt.scatter(X[:,0],X[:,1], c=y_pred, marker='o')
plt.show()