
是因为我的输入数据较少吗还是算法有问题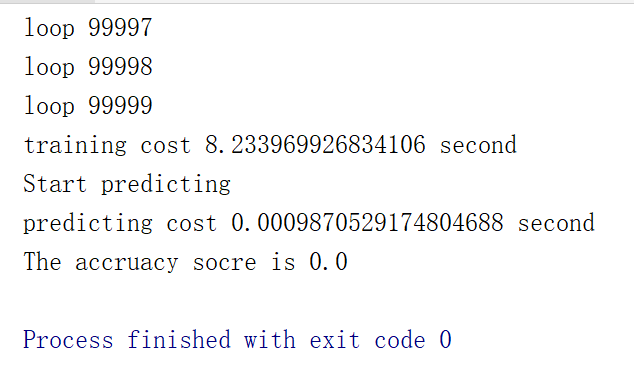
import math
import pandas as pd
import numpy as np
import random
import time
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
class Softmax(object):
def __init__(self):
self.learning_step = 0.000001 # 学习速率
self.max_iteration = 100000 # 最大迭代次数
self.weight_lambda = 0.01 # 衰退权重
def cal_e(self,x,l):
'''
计算博客中的公式3
'''
theta_l = self.w[l]
product = np.dot(theta_l,x)
return math.exp(product)
def cal_probability(self,x,j):
'''
计算博客中的公式2
'''
molecule = self.cal_e(x,j)
denominator = sum([self.cal_e(x,i) for i in range(self.k)])
return molecule/denominator
def cal_partial_derivative(self,x,y,j):
'''
计算博客中的公式1
'''
first = int(y==j) # 计算示性函数
second = self.cal_probability(x,j) # 计算后面那个概率
return -x*(first-second) + self.weight_lambda*self.w[j]
def predict_(self, x):
result = np.dot(self.w,x)
row, column = result.shape
# 找最大值所在的列
_positon = np.argmax(result)
m, n = divmod(_positon, column)
return m
def train(self, features, labels):
self.k = len(set(labels))
self.w = np.zeros((self.k,len(features[0])+1))
time = 0
while time < self.max_iteration:
print('loop %d' % time)
time += 1
index = random.randint(0, len(labels) - 1)
x = features[index]
y = labels[index]
x = list(x)
x.append(1.0)
x = np.array(x)
derivatives = [self.cal_partial_derivative(x,y,j) for j in range(self.k)]
for j in range(self.k):
self.w[j] -= self.learning_step * derivatives[j]
def predict(self,features):
labels = []
for feature in features:
x = list(feature)
x.append(1)
x = np.matrix(x)
x = np.transpose(x)
labels.append(self.predict_(x))
return labels
if __name__ == '__main__':
print('Start read data')
time_1 = time.time()
raw_data = pd.read_csv('E:\jiqi\jiqiqiq.CSV', header=0)
data = raw_data.values
imgs = data[0::, 1::]
labels = data[::, 0]
# 选取 2/3 数据作为训练集, 1/3 数据作为测试集
train_features, test_features, train_labels, test_labels = train_test_split(
imgs, labels, test_size=0.33, random_state=23323)
# print train_features.shape
# print train_features.shape
time_2 = time.time()
print('read data cost '+ str(time_2 - time_1)+' second')
print('Start training')
p = Softmax()
p.train(train_features, train_labels)
time_3 = time.time()
print('training cost '+ str(time_3 - time_2)+' second')
print('Start predicting')
test_predict = p.predict(test_features)
time_4 = time.time()
print('predicting cost ' + str(time_4 - time_3) +' second')
score = accuracy_score(test_labels, test_predict)
print("The accruacy socre is " + str(score))






