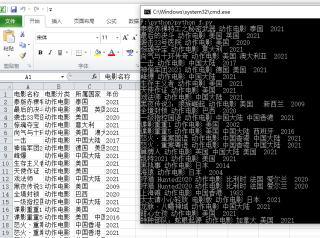
题主要的xpath采集代码如下
import requests
from lxml import etree
from openpyxl import Workbook
wb=Workbook()
ws=wb.active
ws.append(["电影名称","电影分类","所属国家","年份"])
准备url和headers
headers={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.87 Safari/537.36 SE 2.X MetaSr 1.0"}
url="https://www.kkdsa.com/vodtype/6.html%22
response=requests.get(url=url,headers=headers)
使用etree.HTML()将字符串转换成HTML对象
html=etree.HTML(response.text)
print(html)
div_list=html.xpath('//div[@class="cards video-list"]/div')
print(len(div_list))
for div in div_list:
# 获取剧名
name=div.xpath('.//div[@class="card-heading text-ellipsis"]4/a/text()')[0]
# 电影分类
classify=div.xpath('.//div[@clas="card-content text-ellipsis text-muted"]//a/text()')[0]
print(name,classify)