关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
皆明
2021-12-10 11:12
采纳率: 50%
浏览 241
首页
Python
已结题
python爬虫xpath解析返回为空有什么解决方法吗
python
爬虫
问题遇到的现象和发生背景
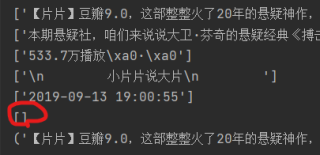
问题相关代码,请勿粘贴截图
运行结果及报错内容
我的解答思路和尝试过的方法
我想要达到的结果
收起
写回答
好问题
0
提建议
关注问题
微信扫一扫
点击复制链接
分享
邀请回答
编辑
收藏
删除
收藏
举报
1
条回答
默认
最新
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
菜猫小六
2021-12-10 11:27
关注
为空的地方xpath主要是为了拿到什么数据,贴一下网页和要拿到的数据,帮你写一下xpath。
上面图上的xpath那么长那么绝对路径,大概率拿不到数据的。
本回答被题主选为最佳回答
, 对您是否有帮助呢?
本回答被专家选为最佳回答
, 对您是否有帮助呢?
本回答被题主和专家选为最佳回答
, 对您是否有帮助呢?
解决
无用
评论
打赏
微信扫一扫
点击复制链接
分享
举报
评论
按下Enter换行,Ctrl+Enter发表内容
查看更多回答(0条)
向“C知道”追问
报告相同问题?
提交
关注问题
Python
爬虫
实战之
xpath
解析
2022-08-01 19:59
阿浩( ̄▽ ̄)的博客
XPath
是一门在XML文档中查找信息的语言,最初是用来搜寻XML文档的,但是它同样适用于HTML文档的搜索。所以在
Python
爬虫
中,我们经常使用
xpath
解析
这种高效便捷的方式来提取信息。
python
爬虫
之
xpath
解析
(附实战)
2020-07-10 18:23
猛男技术控的博客
xpath
是学
爬虫
的必备工具,其选择功能十分强大,它提供了非常简明的路径选择表达式,另外,它还提供了超过100个内建函数,用于字符串、数值、时间的匹配以及节点、序列的处理等,几乎所有我们想要定位的节点,都可以...
利用
PYTHON
爬虫
,
Xpath
路径正确但是
返回
数据为空
2023-12-11 10:43
StaysOnEarth的博客
/tr/td[@class="align_left"]/text()') print(result) 网页源码: 旭明光电 LEDS 1.5 0.24 19.05% 7.34万 1.5 1.24 1.54 1.24 741万 纳斯达克
返回
值: [] Process finished with exit code 0
解析
了几个网站都遇到...
python
爬虫
入门(六)之
xpath
解析
2024-08-16 00:28
橙意满满的西瓜大侠的博客
XPath
(XML Path Language)是一种用于在 XML 文档中查找信息的语言。html是xml的一个子集(XML 允许用户创建自己的标签来描述数据。例如,<book><title>是 XML 标签,可以用于描述书籍信息)。
Xpath
可以用来遍历 ...
Python
爬虫
XPath
解析
出乱码
解决
方法
2021-03-05 20:55
平人的进步日常的博客
请求后加上编码 resp = requests.get(url, headers=headers) resp.encoding = 'GBK'
Python
爬虫
——
XPath
解析
本地html文件
2022-07-26 10:41
万里顾—程的博客
在使用
爬虫
过程中可以用
XPath
来爬取网页中想要的数据。
Xpath
使用简洁的路径表达式来匹配XML/HTML文档中的节点或者节点集,通过定位网页中的节点,从而找到我们需要的数据。
Xpath
提供了100多个内建函数,包括了处理...
python
中
xpath
爬虫
实例详解
2020-09-18 18:18
主要介绍了
python
实例:
xpath
爬虫
实例,本文通过实例代码给大家介绍的非常详细,具有一定的参考借鉴价值,需要的朋友可以参考下
爬虫
利器:
Python
+
Xpath
Helper插件
2024-06-14 15:01
总而言之,
Python
爬虫
加
XPath
Helper插件是一个高效地在网络上收集图片信息的
方法
。定位要收集的内容,将它们下载到本地,处理数据集以便于使用,是
Python
爬虫
的三个基本步骤,在学习和设计
爬虫
时需要注意这些。通过...
python
爬虫
之
xpath
解析
基础
2024-06-02 22:46
杂记铺的博客
python
爬虫
之
xpath
解析
基础
python
爬虫
xpath
出来空值_
Python
爬虫
之数据
解析
(
XPath
)
2021-03-06 16:34
和风木雨的博客
XPath
是一门在 XML 文档中查找信息的语言。
XPath
可用来在 XML 文档中对元素和属性进行遍历,而将 HTML文档转换成 XML文档后,就可以用
XPath
查找 HTML 节点或元素。XML 文档的特点:XML 文档中的每个成分都是一个...
没有解决我的问题,
去提问
向专家提问
向AI提问
付费问答(悬赏)服务下线公告
◇ 用户帮助中心
◇ 新手如何提问
◇ 奖惩公告
问题事件
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
系统已结题
12月23日
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
已采纳回答
12月15日
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
创建了问题
12月10日


 分享
分享 分享
分享 系统已结题
12月23日
系统已结题
12月23日 已采纳回答
12月15日
创建了问题
12月10日
已采纳回答
12月15日
创建了问题
12月10日


