现有两个txt文本文档,A文档: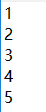 B文档:
B文档: 想要通过python脚本来生成
想要通过python脚本来生成 的文档,实际操作时的数据量比举的例子大得多,所以需要脚本来实现。多谢诸位大大的帮助!
的文档,实际操作时的数据量比举的例子大得多,所以需要脚本来实现。多谢诸位大大的帮助!

python对文本文档的比对和处理

- 写回答
- 好问题 0 提建议
- 追加酬金
- 关注问题
 分享
分享- 邀请回答
-


5条回答 默认 最新
 黑夜中的猫头鹰 2019-05-10 13:52关注
黑夜中的猫头鹰 2019-05-10 13:52关注fp = r'c.txt'
for line_b in open("B.txt", encoding='gb18030', errors = 'ignore'):
num_b = line_b[:line_b.index(";")]
for line_a in open("A.txt", encoding='gb18030', errors = 'ignore'):
if int(num_b) == int(line_a):
with open(fp, 'a') as f:
f.write(line_b)生成结果在c.txt中
本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
- 2021-07-16 09:24回答 2 已采纳 字符串类型就用+号拼接,不是字符串就转下字符串每次追加写入 write(str(a)+str(b))中间如果需要隔开就自己加隔断符号
- 2022-10-02 22:55回答 5 已采纳 这个代码是对的给他点赞 def main(): with open("output.txt", "r") as f1: data1 = f1.read() da
- 2021-01-07 11:44回答 2 已采纳 import codecs import re wf = codecs.open('D:/test.txt', 'w', 'utf-8') wf.write('中华人民共和国中国人民') wf.c
- 2024-07-28 03:35巫德海的博客 python相关学习资料:https://edu.51cto.com/video/3502.htmlhttps://edu.51cto.com/video/1158.htmlhttps://edu.51cto.com/video/4102.htmlPython docx 文本比对:自动化文档差异分析 在处理文档时,经...
- 2022-10-29 00:38回答 2 已采纳 自问自答一下吧, 找了好久发现其实这个看似空的字符串其实是emoji符号里的 Variation Selector,中文译为「变体选择符」 使用 unicode_escape 查看其unicode内存
- 2022-03-18 16:05回答 2 已采纳 import pandas as pd import re df = pd.DataFrame({'Category':['C,D','A,B,C','A,D','C','A,D','A,B,C','
- 2022-02-28 22:04回答 3 已采纳 你第三行的Python 写成了 PyhtonPython 中 t 和h 写反了 如有帮助,请点击我的回答下方的【采纳该答案】按钮帮忙采纳下,谢谢!
- 2024-07-10 03:43睡懒觉星人的博客 Python相关视频讲解:python的or运算...查看python文件_输出py文件_cat_运行python文件_shel如何用Python比对两个文本文件 一、整体流程 首先,我们需要将两个文本文件分别读取出来,然后逐行进行比对,找出差异,并...
- 2022-12-09 00:02回答 2 已采纳 如果使用jupyter notebook可以创建代码单元格,先创建文件 # 导入必要的模块 import os from pathlib import Path # 将当前工作目录设为 D 盘的根目录
- 2021-09-23 18:37回答 1 已采纳 to的是保存,read是读取,根据文件类型区分
- 2021-10-14 21:57回答 1 已采纳 with open('in.txt','r') as f: a=sorted(list(map(int,f.read().split('\n')))) print(a) wit
- 2022-10-13 16:55-小黄怪-的博客 文本比对-python
- 2019-08-10 06:50csvdiff就是利用Python的灵活性和强大的数据处理能力来实现CSV文件的比较。 2. **命令行工具** 命令行接口(CLI)使得csvdiff可以直接在终端中运行,无需图形界面。用户可以通过简单的命令行参数,如文件路径和...
- 2020-12-02 21:21weixin_39531594的博客 python-模糊字符串比较我正在努力完成的是一个程序,该程序读取文件并根据原始句子比较每个句子。 与原始句子完全匹配的句子将得到1分,而与之相反的句子将得到0分。所有其他模糊句子将得到1到0分之间的分数。我不...
- 2024-07-18 10:36极客编程坊的博客 概念 : 在python3中引入了字节串的概念,与str不同,字节串以字节序列值表达数据,更方便用来处理二进程数据。系统自动的在内存中为每一个正在使用的文件开辟一个空间,在对文件读写时都是先将文件内容加载到缓冲区...
- 没有解决我的问题, 去提问



悬赏问题
- ¥15 乌班图ip地址配置及远程SSH
- ¥15 怎么让点阵屏显示静态爱心,用keiluVision5写出让点阵屏显示静态爱心的代码,越快越好
- ¥15 PSPICE制作一个加法器
- ¥15 javaweb项目无法正常跳转
- ¥15 VMBox虚拟机无法访问
- ¥15 skd显示找不到头文件
- ¥15 机器视觉中图片中长度与真实长度的关系
- ¥15 fastreport table 怎么只让每页的最下面和最顶部有横线
- ¥15 java 的protected权限 ,问题在注释里
- ¥15 这个是哪里有问题啊?