
用到的技术点:
1.requests 发送请求 。从服务器获取到数据
2.BeautifulSoup 来解析整个页面的源代码 -> 特简单
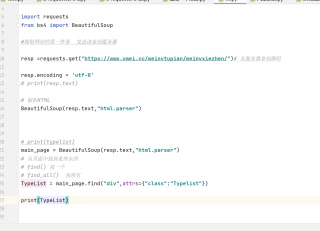
import requests
from bs4 import BeautifulSoup
#爬取网站的第一件事 发送请求到服务器
resp =requests.get("https://www.umei.cc/meinvtupian/meinvxiezhen/")# 从服务器拿到源码
resp.encoding = 'utf-8'
print(resp.text)
解析HTML
BeautifulSoup(resp.text,"html.parser")
print(typelist)
main_page = BeautifulSoup(resp.text,"html.parser")
从页面中找到某些东西
find() 找一个
find_all() 找所有
TypeList = main_page.find("div",attrs={"class":"Typelist"})
print(TypeList)






