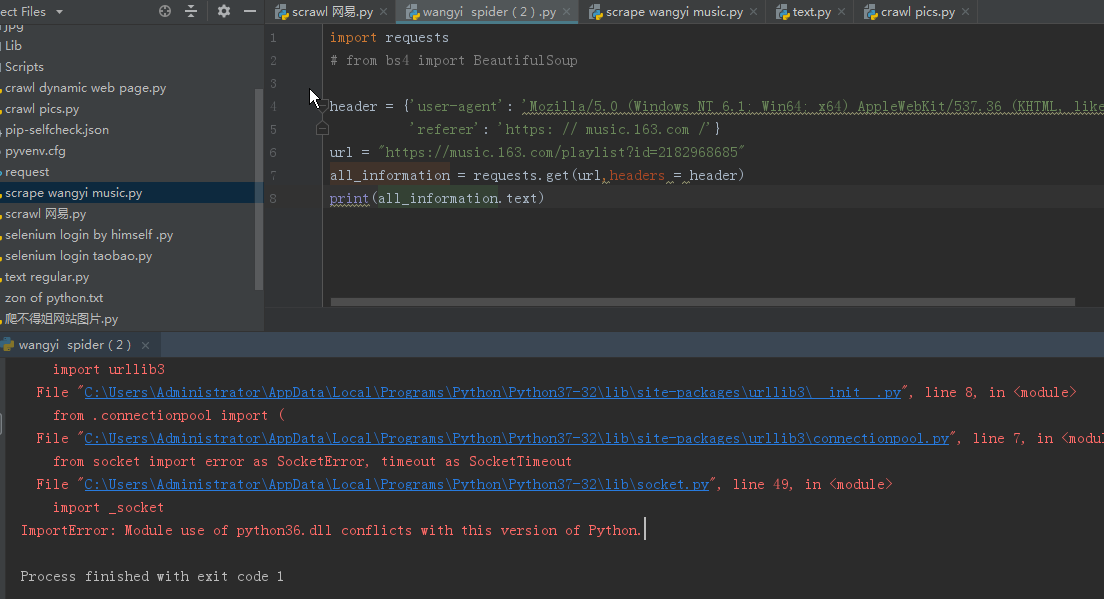
重新安装了requests库,还是这种情况。 获取别的网页也有问题。。
收起
你确定获取别的网页没有问题哦,看看这个有没有用吧:https://bbs.csdn.net/topics/391889199
报告相同问题?

 分享 分享
分享 分享 已采纳回答
1月16日
已采纳回答
1月16日

