


1条回答 默认 最新
 技术专家团-Bamboo 2021-12-23 22:27关注
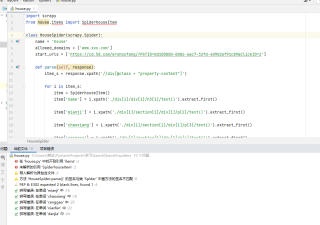
技术专家团-Bamboo 2021-12-23 22:27关注你这个文件是house.py,然后又从这个house引入,改一下文件名
本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
分享
- 2023-07-30 09:59Scrapy是一个强大的Python爬虫框架,它为网络爬虫的开发提供了许多便利的功能,包括高效的数据提取、中间件处理、请求调度以及数据存储等。在使用Scrapy时,我们需要遵循以下步骤来创建和运行一个爬虫项目。 首先,...
- 2024-06-22 16:33懒大王爱吃狼的博客 何为框架,就相当于一个封装...scrapy是基于twisted框架开发而来,twisted是一个流行的事件驱动的python网络框架,scrapy使用了一种非阻塞(又名异步)的代码实现并发的,Scrapy之所以能实现异步,得益于twisted框架。
- 2025-04-08 22:21木觞清的博客 它提供了完整的爬虫开发工具,包括请求管理、数据解析、存储和异常处理等功能,适用于数据挖掘、监测和自动化测试等场景。通过灵活的中间件和管道机制,Scrapy 可以轻松扩展功能(如代理池、分布式爬取)。如果你...
- 2024-12-11 11:34Scrapy是一个基于Python的开源和协作的框架,主要用于爬取网站数据和提取结构化数据的应用,例如网页抓取。Scrapy被广泛用于数据挖掘、信息监控、自动测试等。Scrapy架构设计得非常精巧,拥有清晰的组件层次结构,...
- 2024-07-06 23:16WishYouAFortune的博客 Scrapy,Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。...Scratch,是抓取的意思,这个Python的爬虫框架叫Scrapy,大概也是这个意思吧,就叫它:小抓抓吧。
- 2020-09-09 02:30在Python的世界里,爬虫开发是一项常见的任务,用于自动化地抓取互联网上的数据。...希望这个教程对你在学习Python爬虫和Scrapy框架的过程中有所帮助,同时也鼓励你进一步探索更复杂的爬虫项目和数据处理技术。
- 2022-11-28 19:35代码输入中...的博客 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍。所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等)的具有很强通用性的项目模板。对于...
- 2023-01-09 18:20Shinersmile的博客 在scrapy中,会专门定义一个用于记录数据的类,实例化一个对象,利用这个对象来记录数据。每一次,当数据完成记录,它会离开spiders,来到Scrapy Engine(引擎),引擎将它送入Item Pipeline(数据管道)处理。定义...
- 2024-02-04 08:49### Python爬虫Scrapy实例详解 #### 创建Scrapy项目 Scrapy是一款强大的开源网页抓取框架,被广泛应用于数据采集领域。本文档旨在通过一个具体的示例,详细讲解如何使用Scrapy创建并运行一个基本的爬虫项目。 ###...
- 2021-08-09 11:30孤寒者的博客 【Python爬虫必备—>Scrapy框架快速入门篇——上】
- 没有解决我的问题, 去提问


问题事件
 系统已结题
1月1日
系统已结题
1月1日 已采纳回答
12月24日
已采纳回答
12月24日-
创建了问题
12月23日