爬虫问题,xpath拿出了一个列表,但是列表里面缺失了一个数据,循环拿出的时候,因为其他数据都是十个,而那个数据只有9,导致索引错误,有没有办法解决,如果那个缺失数据的位置在中间5,6的位置,能不能用其他代替,因为如果不代替,比如第6个数据和其他第五个数据就匹配上了,这样就导致数据不准确,问问各位什么好的方法解决吗?


3条回答 默认 最新
 taki0 2021-12-30 20:37关注
taki0 2021-12-30 20:37关注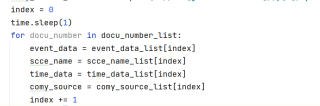
我是这样从把xpath获取的数据拿出来的本回答被题主选为最佳回答 , 对您是否有帮助呢?解决 无用评论 打赏举报 分享
分享
- 2020-09-19 19:07# 假设str1是从HTML文档中通过XPath获取的标签 inner_content = getinnerhtml(str1) print(inner_content) # 输出: OK[推荐] ``` 在这个例子中,`getinnerhtml`函数通过查找开始和结束标签的位置来截取`str1`中的...
- 2022-11-12 14:10dddpppppp的博客 (因为很让我觉得头疼的就是我想爬的那个网站的源代码和elements不一样,不仅如此,源代码写的还很不方便看,例如一行整整几十列,感觉是故意的:(,从源代码里看非常费劲)从前往后依次尝试//*[@id="__layout"]/div...
- 2025-09-02 14:53Python游侠的博客 本教程详细解析XPath语法,包括节点选择、路径表达式、谓词和函数,通过丰富HTML示例演示应用场景,并在Python中使用lxml库提供代码实例和性能优化技巧,帮助读者掌握高效数据提取技术。
- 2022-08-01 19:59阿浩( ̄▽ ̄)的博客 XPath是一门在XML文档中查找信息的语言,最初是用来搜寻XML文档的,但是它同样适用于HTML文档的搜索。所以在Python爬虫中,我们经常使用xpath解析这种高效便捷的方式来提取信息。
- 2021-04-26 18:42国服露娜的博客 所以我有了这个link,我试图从XPath //div[@class='titlu']中获取文本,但由于某些原因,有时我得到的文本应该是什么样子,而有时我收到的是一个空字符串,即使站点包含该文本。在我尝试了什么:wait = ...
- 2020-09-20 22:36本篇文章将深入探讨在使用Python的`lxml`库解析HTML文档并使用XPath时,遇到`<Element a at 0x39a9a80>`这样的输出时应该如何理解和处理。 首先,`<Element a at 0x39a9a80>`并不是一个字符串,而是一个对象的表示...
- 2024-05-14 22:18会逃跑的乌龟的博客 本文章主要介绍使用python,通过requests+Xpath 爬虫的技术学习和实例。
- 2024-05-03 02:002401_84692456的博客 [在这里插入图片描述](https://img-blog.csdnimg.cn/f5aeb4050ab547cf90b1a028d1aacb1d.png#pic_center) **网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正...
- 2022-06-16 23:18锐昆的博客 最近学习研究Scrapy,刚好遇到爬取文章正文内容,总是搞不定innerHTML 方法 找了很多,都是你抄我,我抄你的,也没有一个人验证的,最终只能自己实践,最终实现了获取节点下辖内容,记录一下,说不定以后要用的: ...
- 2024-04-30 15:002301_82243493的博客 为了更加深入地学习和运用好这两大工具,下面以爬取Tencent招聘网站职位信息为实例介绍在实践中基于Xpath和lxml库编写爬虫的基本流程和方法。Tencent招聘网址:https://hr.tencent.com/进入网站后,我们来浏览一下...
- 没有解决我的问题, 去提问


问题事件
 系统已结题
1月13日
系统已结题
1月13日 已采纳回答
1月5日
已采纳回答
1月5日-
创建了问题
12月30日