问题遇到的现象和发生背景
爬取某网站的新冠数据,通过lxml包中的xpath进行爬取内容分析,发现无法分析得所要内容。
问题相关代码,请勿粘贴截图
import requests
from lxml import etree
url = "https://www.worldometers.info/coronavirus/"
res = requests.get(url).content
html = etree.HTML(res)
temp_list = {}
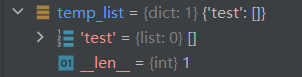
temp_list["test"] = html.xpath('/html/body/div[2]/div[3]/div/div[6]/div[1]/div/table/tr[7]/td[2]/a')
pass
运行结果及报错内容
如图所示,无法分析得所要内容:
我的解答思路和尝试过的方法
首先确认所要数据在静态页面中而非动态返回,且res中存在所要数据。
其次,经过网上查询,发现xpath在处理tbody时会出错,故按照网上的说法删除掉了tbody标签,但是依然报错,不知因何原因导致。