

问题遇到的现象和发生背景
问题相关代码,请勿粘贴截图
#导入包
import requests
import re
#请求网址
url = "https://www.vmgirls.com/18236.html"
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'}
resp=requests.get(url, headers=headers)
html = resp.text
#解析网址
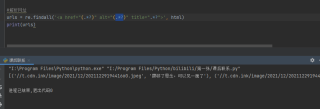
urls = re.findall('<a href="(.*?)" alt="(.*?)" title=".*?">', html)
# print(urls)
网站源码没有http图片

网站源码代码
<a href="//t.cdn.ink/image/2021/12/2021122919442214.jpeg" alt="攒够了思念,可以见一面了" title="攒够了思念,可以见一面了"><img alt="攒够了思念,可以见一面了-唯美女生" src="//t.cdn.ink/image/2021/12/2021122919442214.jpeg" alt=""/></a>
打印 带上 http:得到超链接 我想要达到的结果








