问题遇到的现象和发生背景
最后print输出结果为空
问题相关代码,请勿粘贴截图
#先用requests拿到页面源代码
#通过re正则提取有效=信息
import requests
import re
url = "https://movie.douban.com/top250"
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36'
}
qinqiu =requests.get(url,headers=headers)#将url打开然后才能text爬取
#用headers进行反反爬策略绕过机器验证
page_content = qinqiu.text #将页面源代码赋值给page_content
#解析数据
obj =re.compile(r'<li>.*?<div class="item">.*?<span class="title">(?P<name>.*?)</span>')
objs = obj.finditer(page_content)
for yu in objs:
print(yu.group('name'))
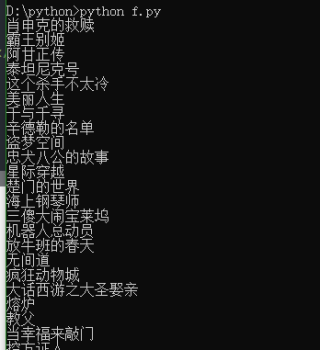
运行结果及报错内容
运行结果为空无报错
我的解答思路和尝试过的方法
我先print了一下页面源代码是没问题的
我想要达到的结果