想要爬取当当图书网页的评论信息
评论页并不是一个url,而是一个javascript
如图:
这些评论信息在源代码是不显示的,返回的形式是在network里边的XHR
如图: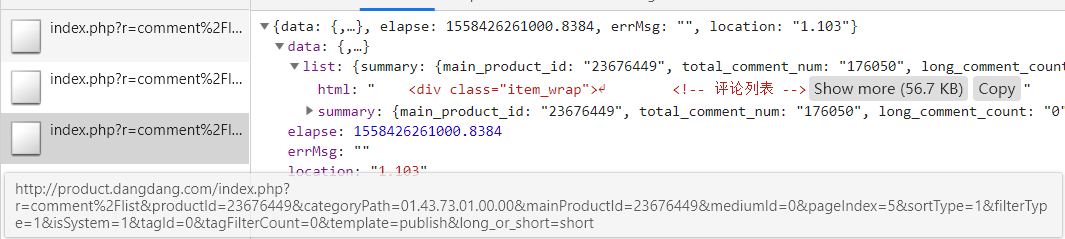
我需要对这个文件进行解析提取一些数据,并且我想找到一个办法能够获得这本书的评论下的所有的XHR文件
各位大佬能不能教教我

想要爬取当当图书网页的评论信息
评论页并不是一个url,而是一个javascript
如图:
这些评论信息在源代码是不显示的,返回的形式是在network里边的XHR
如图:
我需要对这个文件进行解析提取一些数据,并且我想找到一个办法能够获得这本书的评论下的所有的XHR文件
各位大佬能不能教教我
 分享
分享




