
代码是求这几个数字的最大值
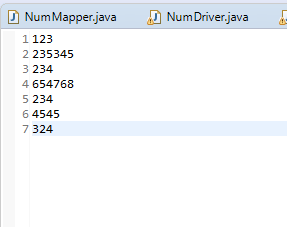
下面是我的代码
Mapper
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class NumMapper extends Mapper<LongWritable, Text, LongWritable, LongWritable> {
public void map(LongWritable ikey, Text ivalue, Context context) throws IOException, InterruptedException {
String line=ivalue.toString();
long num = Long.parseLong(line);
context.write(new LongWritable(1), new LongWritable(num));
}
}
Combiner
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import io.netty.handler.codec.http.HttpHeaders.Values;
public class NumCombiner extends Reducer<LongWritable, LongWritable, LongWritable, LongWritable> {
@Override
protected void reduce(LongWritable key, Iterable<LongWritable> value,
Reducer<LongWritable, LongWritable, LongWritable, LongWritable>.Context context)
throws IOException, InterruptedException {
Iterator<LongWritable> iter=value.iterator();
long max=Long.MIN_VALUE;
while(iter.hasNext()) {
long tmp=iter.next().get();
max =tmp>max?tmp:max;
}
context.write(new LongWritable(1), new LongWritable(max));
}
}
Reducer
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class NumReducer extends Reducer<LongWritable, LongWritable, LongWritable, NullWritable> {
public void reduce(Text _key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
Iterator<LongWritable> ite =values.iterator();
long num=0;
if(ite.hasNext()) {
num=ite.next().get();
long now =ite.next().get();
num=now>num?now:num;
}
context.write(new LongWritable(num), NullWritable.get());
}
}
Driver
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class NumDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "JobName");
job.setJarByClass(MaxMin.NumDriver.class);
job.setMapperClass(MaxMin.NumMapper.class);
job.setReducerClass(MaxMin.NumReducer.class);
job.setCombinerClass(NumCombiner.class);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(LongWritable.class);
job.setOutputKeyClass(LongWritable.class);
job.setOutputValueClass(NullWritable.class);
FileInputFormat.setInputPaths(job, new Path("hdfs://192.168.77.81:9000/park1/num.txt"));
FileOutputFormat.setOutputPath(job, new Path("hdfs://192.168.77.81:9000/park2/MaxMin"));
if (!job.waitForCompletion(true))
return;
}
}
我的问题是 如果我注销了在Driver中Combiner的那行代码 我的输出结果就会变成这样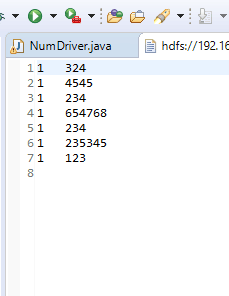
正常如果写了combiner的输出是这样的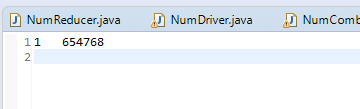
我想问问为啥会这样 因为按照我的理解是combiner只是进入reduce之前的一个本地聚合 并不是一个会影响输出结果的东西 麻烦来个大神解释一下~







