关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
阿黄Ahuang
2022-01-14 09:55
采纳率: 50%
浏览 13
首页
Java
已结题
大数据怎么保证采集器到Spark中数据一致性
java
大数据
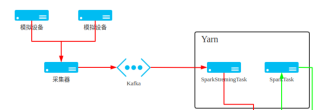
如图从采集器到Yarn通过kafka进行数据传输,需要进行数据的预处理验证,确保源数据和推送到Hadoop中的数据一致
所以需要验证采集器到Yarn的数据是一致的(应该是吧)
那应该怎么验证呢?
我看到有说可以用md5sum校验数据文件,但是从采集器经过Kafka传输到Spark这个过程是传数据呀,没有传文件呀
收起
写回答
好问题
0
提建议
关注问题
微信扫一扫
点击复制链接
分享
邀请回答
编辑
收藏
删除
收藏
举报
0
条回答
默认
最新
查看更多回答(-1条)
向“C知道”追问
报告相同问题?
提交
关注问题
大数据
平台
数据
一致性
监控与告警系统设计
2025-05-10 23:05
光子AI的博客
随着企业数字化转型的深入,
大数据
平台承载着PB级
数据
的采集、存储、处理和分析任务。分布式架构下,
数据
在多
数据
源同步、ETL流程、分布式存储副本同步等环节易出现不一致问题,导致报表错误、业务逻辑异常甚至决策...
大数据
治理域——日志
数据
采集设计
2025-05-13 23:43
庄小焱的博客
本文主要介绍了Web页面端日志采集的设计。首先阐述了页面浏览日志采集,包括客户端日志采集的实现方式、采集内容及技术亮点。...最后探讨了日志采集的挑战与解决方案,以及日志采集前置到用户终端的相关问题。
大数据
领域
数据
采集的必备工具推荐
2025-05-17 16:16
光子AI的博客
本文聚焦结构化
数据
(
数据
库)、半结构化
数据
(XML/JSON)、非结构化
数据
(网页/日志)三
大数据
源,覆盖批量采集、实时流采集、API接口采集、网络爬虫四大核心场景,系统评测20+主流工具的技术特性,提供从工具选型...
大数据
与物联网:半结构化
数据
的采集与分析实践
2025-05-07 18:11
光子AI的博客
这类
数据
兼具结构化(可定义模式)与非结构化(模式灵活多变)的特性,传统关系型
数据
库难以高效处理,需针对性设计
数据
采集、存储与分析方案。如何设计高可靠的半结构化
数据
采集管道?分布式计算框架如何高效解析与...
大数据
时代:如何构建高效的
数据
中
台架构?
2025-05-08 01:19
光子AI的博客
本文聚焦
数据
中
台架构设计的核心技术体系,覆盖从底层
数据
接入到上层业务服务的全链路,提供技术选型、组件集成、治理规范等实操指南,适用于大
中
企业
数据
团队构建数字化转型基础设施。本文采用"概念解析→技术架构...
Java
大数据
与区块链的融合:
数据
可信共享与溯源(45)
2025-01-14 22:51
青云交的博客
文章深入探讨了
Java
大数据
与区块链的融合,阐述了融合的背景意义、技术实现方式、应用案例,分析了面临的挑战并展望未来,旨在实现
数据
可信共享与溯源。
大数据
领域
Spark
的
数据
源管理与监控
2025-09-21 02:27
AI 搜索引擎技术的博客
在
大数据
生态系统
中
,
数据
源的管理与监控是确保
数据
处理质量和效率的关键环节。Apache
Spark
作为主流的
大数据
处理框架,其
数据
源管理能力直接影响着整个
数据
处理流程的可靠性和性能。系统梳理
Spark
的
数据
源管理体系...
优化
大数据
领域
数据
一致性
的流程与方法
2026-02-20 20:31
AI量化价值投资入门到精通的博客
分层治理:从
数据
源到消费层,每个环节用针对性的方案解决问题;...但只要你建立了完整的流程体系,就能从容应对
大数据
中
的
一致性
挑战。如果你在实践
中
遇到问题,欢迎在评论区留言——我会尽我所能帮你解决!
数据
中
台测试方法论:
大数据
平台质量保障体系
2025-04-27 14:30
光子AI的博客
随着企业
数据
量呈指数级...本文聚焦
数据
中
台测试的全流程方法论,覆盖
数据
采集、存储、计算、服务四大核心环节,目标是为技术团队提供可落地的质量保障体系设计框架。核心概念:定义
数据
中
台测试的关键要素与层级关系;
大数据
领域实时分析:保障
数据
时效性的重要手段
2025-05-09 03:13
AI大数据智能洞察的博客
大数据
的规模、多样性和高速性对传统的
数据
处理和分析方法提出了巨大挑战。
大数据
领域的实时分析旨在及时从海量
数据
中
提取有价值的信息,以支持实时决策。本文章的范围涵盖了
大数据
实时分析的各个方面,包括核心概念...
没有解决我的问题,
去提问
向专家提问
向AI提问
付费问答(悬赏)服务下线公告
◇ 用户帮助中心
◇ 新手如何提问
◇ 奖惩公告
问题事件
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
系统已结题
1月22日
关注
码龄
粉丝数
原力等级 --
被采纳
被点赞
采纳率
创建了问题
1月14日

 分享
分享 系统已结题
1月22日
系统已结题
1月22日 创建了问题
1月14日
创建了问题
1月14日

